[翻译] JDK 16 中的 ZGC
JDK 16 中的 ZGC
原文链接:What’s new in JDK 16
JDK 16 已经发布。与往常一样,新版本 JDK 会带来一系列新功能、功能增强以及 bug 修复。在这个版本中 ZGC 有 46 个功能增强以及 25 个 bug 修复。这里我会介绍一些更有趣的增强功能。
摘要
- 通过并行线程栈扫描,ZGC 现在暂停时间是微秒级别,平均暂停时间约为 50 微秒,最大暂停时间约为 500 微秒。暂停时间不受堆、活动集和根集大小的影响。
- 不再保留堆区域,ZGC 在需要时进行就地移动。这节约了内存,同时也能保证堆在所有情况下都能成功压缩。
- 转发表现在更有效地进行分配和初始化,这缩短了完成 GC 周期所需的时间,特别是在收集稀疏的大型堆时。
亚毫秒级最大暂停时间
(又称并发线程栈处理)
当我们开始开发 ZGC 项目时,我们的目标是让 GC 暂停时间永远不超过 10 毫秒。在当时,10 毫秒似乎是一个很有野心的目标。Hotspot 上提供的其他 GC 算法通常会产生比这更糟糕的最大暂停时间,尤其是在使用大堆时。实现这一目标最重要的是并行处理所有繁重的操作,例如移动(relocation)对象、引用处理以及类卸载。那时候 Hotspot 缺乏并行处理它们所需的基础设施,所以需要花费几年的开发时间实现它们。

在达到最初的 10 毫秒目标后,我们重新确定了一个更具雄心的目标。也就是说,GC 的暂停时间应该永远不超过 1 毫秒。从 JDK 16 开始,我很高兴地向大家报告,我们达到了这个目标。ZGC 现在有着 O(1) 的暂停时间。换句话说,它以恒定的时间执行,并且不随着堆、活动集合(live-set)和根集合(root-set)的大小(和其他内容)增加而增加。当然,我们依然任由操作系统分配 GC 线程的 CPU 时间。但是只要您的系统没有过度配置,您就可以看到 GC 的平均暂停时间约为 0.05 毫秒(50 微秒),最大暂停时间约为 0.5 毫秒(500 微秒)。
所以,我们是怎么做到的?在 JDK 16 之前,ZGC 的暂停时间仍然与根集合的一个子集的大小相关。更准确的说,我们仍然在 Stop-The-World 阶段扫描线程栈。这意味着如果 Java 应用有着大量的线程,那么暂停时间就会增加。如果这些线程有着很深的调用栈,那么暂停时间会增加更多。从 JDK 16 开始,对线程栈的扫描是并行处理的,也就是说在扫描栈的时候应用程序可以同时运行。
正如您的想象,在线程运行时在堆栈里进行扫描需要一些“魔法”。这是通过一种被称为栈水印屏障(Stack Watermark Barrier)的技术实现的。简而言之,这是一种防止 Java 线程在栈帧中没有先检查是否安全就返回的机制。这是一个开销很低的检查,包括在已经存在的方法返回时的安全点检测中。概念上来说,您可以将它视为栈帧的读屏障,在需要的时候它会强制 Java 线程在栈帧返回前采取某种类型的操作,使其进入安全状态。每个 Java 线程都有一个或者多个栈水印,它告诉栈没有特殊操作的情况下的安全行程。要通过水印,需要采取慢路径操作,将一个或者多个帧置于安全状态,并更新水印。让所有线程栈进入安全状态通常需要一个或者多个 GC 线程,但因为这是并行进行的,在 Java 线程线程想要返回到 GC 尚未到达的帧时,它需要修复一些自己的帧。如果您多更多细节感兴趣,请查看 JEP 376: ZGC: Concurrent Thread-Stack Processing,它描述了这项工作。
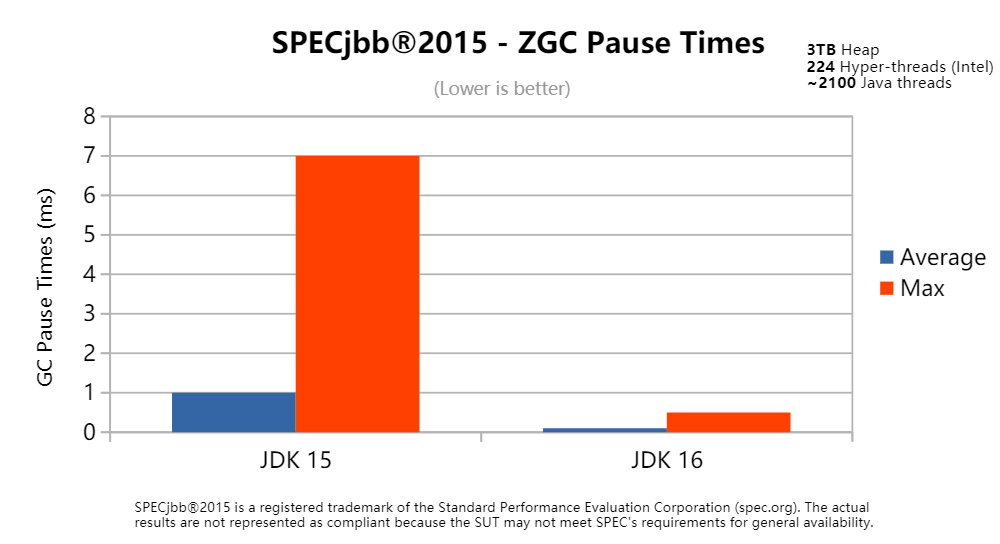
随着 JEP 376 的完成,现在 Stop-The-World 阶段 ZGC 扫描的根为 0。对于很多工作负载,即使在 Java 16 之前您也能看到非常低的最大暂停时间。但是如果您在一台大型计算机上运行,并且您的工作负载有大量线程,您依然会发现最大暂停时间会远远超过 1 毫秒。为了形象地展示这项改进,下面是一个比较 JDK 15 和 JDK 16 的样例,它在一个有几千个线程的大型机器上运行 SPECjbb®2015。
就地移动
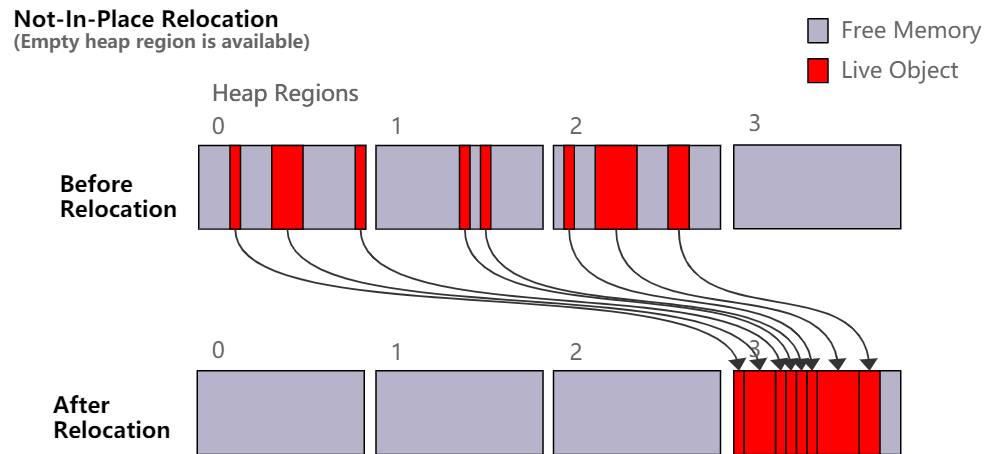
在 JDK 16 中,ZGC 支持了 就地移动(in-place relocation)。这个功能避免了在堆已满的情况下需要 GC 回收垃圾时产生 OutOfMemoryError 。通常 ZGC 通过将可紧凑打包(densely packed)的对象从较稀疏的堆区域移动到一个或多个空的堆区域来压缩堆(由此释放内存)。这种策略很直接且简单,并且非常适合并行处理。但是,它有一个缺点。它需要一些空闲内存(每个大小的类型都至少要一个空的堆区域)才能开始移动 过程。如果堆已满,也就是所有堆区域都在使用中,那么我们就无处移动对象。
在 JDK 16 之前,ZGC 通过保留堆(heap reserve)来解决这个问题。保留堆是一组堆区域,这些区域被预留出来,不用于 Java 线程中的常规堆分配,只允许 GC 在移动对象时使用保留堆。这确保有空的堆区域可用,即使在 Java 线程眼中堆已满,也可以开始移动过程。保留堆空间通常是堆中的一小部分, 在一篇以前的博客中,我写了在 JDK 14 中如何改进了它以更好的支持小堆。
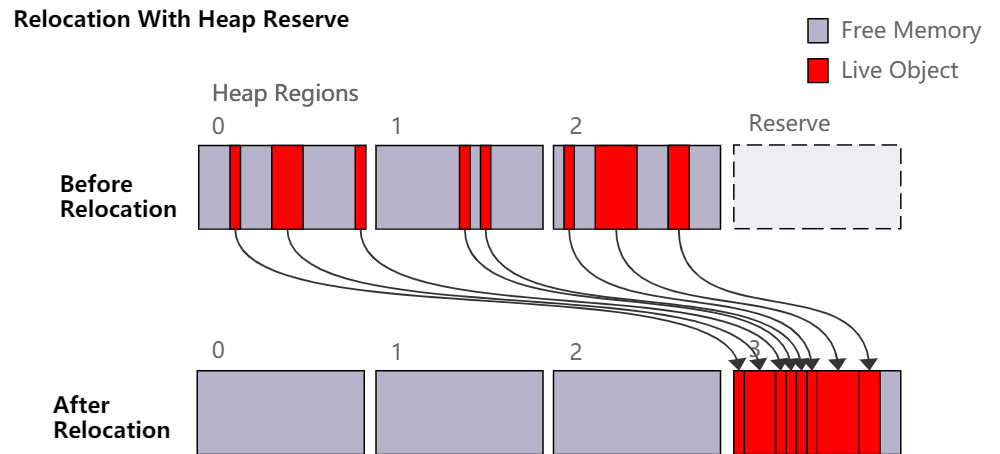
尽管如此,保留堆依然存在一些问题。例如,保留堆对于执行移动的 Java 线程不可用,所以无法强制保证 移动过程可以完成,GC 能由此回收(足够的)内存。这对于几乎所有正常的工作负载来说都不是问题,但我们的测试表明构建一个能引发这个问题的程序是可能的,这又会提前引发 OutOfMemoryError。另外提前保留堆的一部分(尽管这部分很小)对于大多数工作负载来说都是浪费内存。
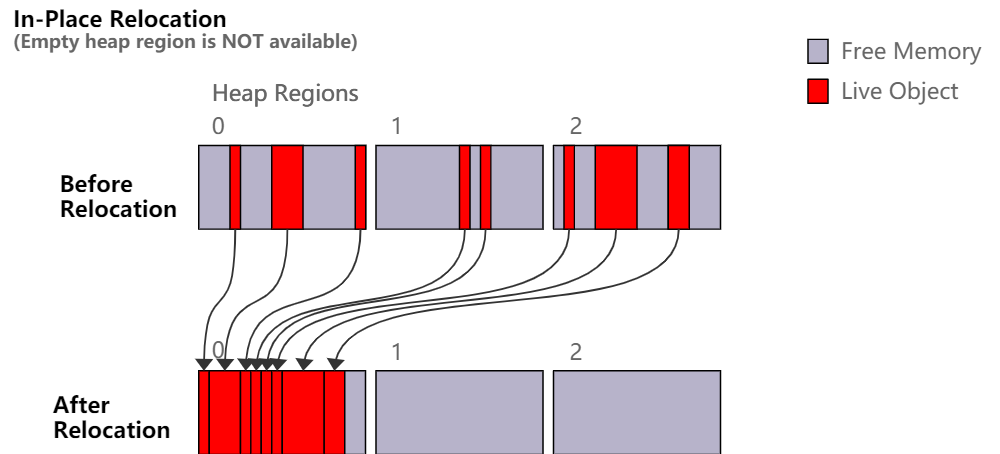
另一种释放连续内存块的方法是就地压缩堆。其他 Hotspot 收集器(例如 G1、Parallel 和 Serial)在执行所谓的 Full GC 时会执行某种版本的这个操作。这种方法的优点是不需要额外内存来释放内存。换句话说,它可以愉快地压缩满地堆,而不需要某种保留堆。
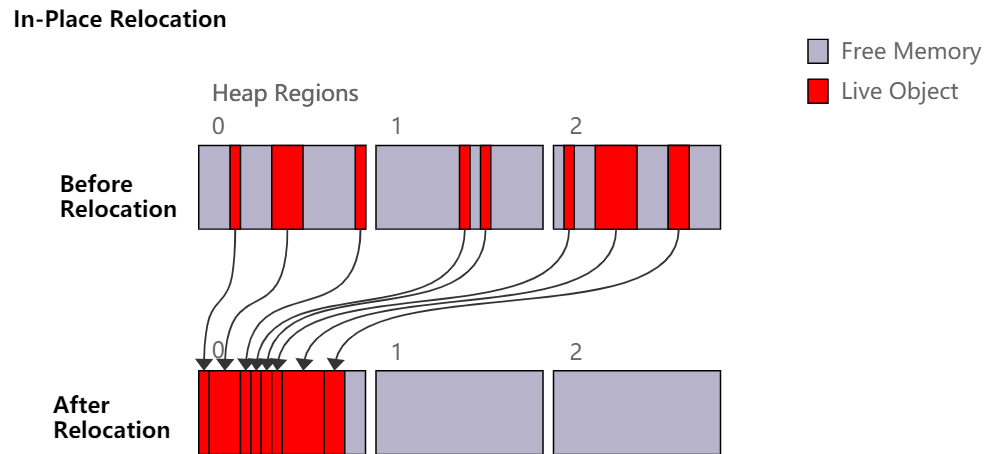
然而就地压缩堆仍然有一些挑战,并且通常会带来一些开销。例如,移动对象对象的顺序很重要,否则可能会覆盖尚未移动的对象。这需要 GC 线程之间更多的协作,不利于并行处理,同时这还影响 Java 线程在 GC 移动对象时能做什么和不能做什么。
总而言之,这两种方法都有自己的优点。当有可用的空堆区域时,不就地移动通常执行得更好,而就地移动可以保证移动过程即使在没有空堆区域可用时依然能成功完成。
JDK 16 开始 ZGC 同时使用这两种方法来同时获得二者的好处。这使我们不需要保留堆,同时在通常情况下保持良好的移动性能,并保证在边缘情况下总是能成功完成移动。默认情况下,只要有空的堆区域可用于移动对象,ZGC 就不会就地移动对象。如果没有空堆区域,ZGC 就会切换到就地移动。一旦空堆区域可用,ZGC 将在此切换为不就地移动的状态。
这些移动模式之间切换是无缝的,如果需要,可以在同一个 GC 中多次进行切换。当然,大多数工作负载中永远不会遇到需要切换的情况,但是知道 ZGC 能够很好的处理这些情况并且不会因为无法压缩堆而过早抛出 OutOfMemoryError 应该会让人更放心。
ZGC 日志也增加了对每个大小组(Small/Medium/Large)中有多少个堆区域(ZPages)被原地移动的显示。下面是一个示例,其中有 54MB 的小对象需要移动,3 个小页面需要就地移动。
1
2
3
4
5
...
GC(15) Small Pages: 120 / 240M, Empty: 0M, Relocated: 54M, In-Place: 3
GC(15) Medium Pages: 2 / 64M, Empty: 0M, Relocated: 0M, In-Place: 0
GC(15) Large Pages: 1 / 4M, Empty: 0M, Relocated: 0M, In-Place: 0
...
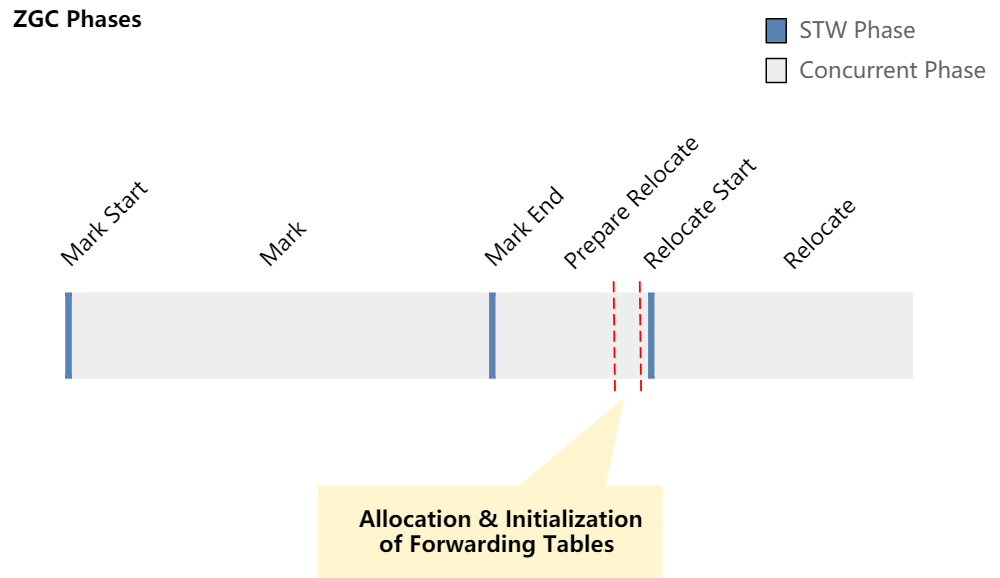
转发表的分配和初始化
当 ZGC 移动对象时,该对象的新地址会被记录在转发表中,该表是在 Java 堆以外分配的数据结构。每个被选为移动集(需要压缩以释放内存的堆区域集)一部分的堆区域都会得到一个与其关联的转发表。
在 JDK 16 之前,当移动集非常大的时候,转发表的分配和初始化可能会占用 GC 周期中的很大一部分时间。移动集的大小与移动过程期间移动的对象数量相关。例如,如果您有一个大于 100GB 的堆,并且工作负载中会产生大量的碎片,在堆中均匀的分布着小的孔隙,那么移动集会很大,分配/初始化它可能需要一段时间。当然这个工作始终在并发阶段进行,因此它不会影响 GC 暂停时间。不过这里也还有改进的余地。
在 JDK 16 中,ZGC 现在会批量分配转发表。现在我们不再会多次(可能有几千次)调用 malloc/new 给每个表分配内存,而是一次性分配所有表的所需内存。着通常有助于避免分配开销和潜在的锁竞争,并显著地减少分配这些表所需的时间。
这些表的初始化是另一个瓶颈。转发表是一个哈希表,因为初始化它需要设置一个小的表头,并要将一个(可能很大的)转发表 entry 数组清零。从 JDK 16 开始,ZGC 使用多个线程(而不是单个线程)并行地进行初始化。
总而言之,这些变更显著减少了分配和初始化转发表所需的时间,特别是在收集一个很大的、内容稀疏的堆时,所需时间可能会降低一个甚至两个数量级。