[翻译] Babylon OpenJDK: HAT GPU 编程入门指南以及与 TornadoVM 的对比
Babylon OpenJDK: A Guide for Beginners and Comparison with TornadoVM
原文链接:Babylon OpenJDK: A Guide for Beginners and Comparison with TornadoVM
简介
Babylon 是一个新的 OpenJDK 项目,旨在增强 Java 平台的代码反射功能, 使其不仅能用于查询类和字段,还能获取方法体和 lambda 表达式内的代码结构。 这个项目的最终目标是让用户能在不使用任何第三方库的情况下对代码进行转换。
这在实践中意味着什么?经过增强的代码反射可用于表示不同类型的计算,例如自动微分 [2]、LINQ 表达式 [3],甚至 GPU 分载(也是本文的重点)。 我们在本文中将会介绍 Babylon 如何帮助开发人员在 Java 中定义 GPU 编程的并行框架,以及它与 TornadoVM 等现有的解决方案的不同之处。
在深入了解 Babylon 中调用 GPU 的流程之前,我们先来定义一个关键术语–代码模型(Code Model)。
在 Babylon 的语境里,代码模型是程序代码的一种表示形式,包含类型和控制流等信息,由 javac 编译器生成并存储于类文件中。
经过 Babylon 增强的反射 API 使开发者能够在运行时访问和操作这些代码模型,从而直接在 Java 中实现元编程。
使用它可以动态生成和操作 Java 程序,比如可以为 Intel/NVIDIA GPU 等各种硬件加速器生成定制的 GPU 代码。 事实上,这正是 Babylon 的子项目 HAT(异构加速器工具包,Heterogeneous Accelerator Toolkit)的目的, 它基于 Babylon 为 Java 平台提供了 GPU 后端。
本文中将探讨开发人员该如何使用 HAT 调用 GPU 进行硬件加速。 我们将会深入探讨支持这一功能的关键 API,并解释代码是如何执行的。
然后我还会对比 HAT 与 TornadoVM。 TornadoVM 是一个 Java 并行编程框架,可以让 Java 透明地调用 GPU 等现代硬件实现数据并行加速处理。
利益相关 :我(本文原作者 Juan Fumero)是 TornadoVM 项目的架构师和首席开发者之一。 虽然如此,我对于 HAT 的探索完全是出于对这一新兴技术的好奇和探索欲。 我的目标是对这两个项目进行客观的比较,在比较中我会尽力做到公平公正, 如果你觉得有任何偏颇的地方,欢迎进行反馈和讨论。
说完这些,让我们开始吧!
HAT: 异构加速器工具包
本博文反映的是 Babylon 项目截至 2025 年 2 月的状态。 由于该项目正在快速发展,某些示例在未来的版本中可能无法正确编译或运行。 不过,本文介绍的核心概念和基本理解对读者来说仍有价值。
HAT 提供了不同的接口来构建针对 GPU 执行而定制的应用程序。HAT 接口分为三类:
- 帮助开发人员表达并行 Kernel 的
NDRangeKernel API。 - 用于在 Java 和硬件加速器之间映射内存的 Java 接口(它们被称为
iFaceMapper)。 - 用于识别需要在 GPU 上加速的方法的 API。
让我们简要了解一下这些组件。
NDRange API
HAT 基于 SIMT(单指令、多线程)模型,而 NDRange API 是用于让 Java 开发者针对此模型创建并行 Kernel 的接口。 在 SIMT 模型中,一条指令同时在多个线程上运行,其中每个线程可以访问不同的数据。 这种 SIMT 模型也是其他 GPU 编程接口和语言(如 CUDA、OpenCL 和 SYCL)的基础。
在 HAT 中,Java 开发人员使用 NDRange API 来定义 Kernel(将要分载到 GPU 上的方法)。 Kernel 封装了每个线程要完成的工作,而 NDRange 则定义了将要运行的线程数量。 这种编程模型中,代码与 GPU 实际的核心数无关,所以有很好的可扩展性。
让我们写一个简单的例子:向量加法。在 Java 中,向量加法可以这样实现:
1
2
3
4
5
public void vectorAddition(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = a[i] + b[i];
}
}
为了清楚起见,我们做两个假设:所有向量都不是空的,并且具有相同的大小。 这些假设简化了问题,让我们能专注于核心概念。 下面是 Babylon/HAT 代码:
1
2
3
4
5
6
@CodeReflection
public void vectorAddition(F32Array a, F32Array b, F32Array c, KernelContext context) {
int idx = context.x;
float sum = a.array(idx) + b.array(idx);
c.array(idx, sum);
}
这个例子演示了一个显式并行 Kernel。
相较于上个例子,这个例子中有几个关键的变化值得注意:
- 注解:需要一个新注解(
@CodeRefection)来指示 javac 编译器生成代表整个方法的代码模型。 - 类型变化:参数类型从
float[]变为F32Array。F32Array是 HAT 提供的类型,用于表示与 GPU 兼容的数据结构。 我们将在下一节深入探讨 HAT 的类型系统和内存管理。 KernelContext:引入了一个新参数–KernelContext。 这个特殊对象用于访问 GPU 内置的 intrinsic,包括线程 ID 和像线程的最大数量这样的 GPU 执行参数。- 基于线程执行:不再需要 for 循环,取而代之的是使用从 Kernel Context 中获取的线程 ID 来访问数据。 这是一种标准的 GPU 编程范式:启动的线程数通常与输入数组的大小相对应。
熟悉 CUDA、OpenCL 或 oneAPI 的人会发现这种代码结构非常熟悉。 在比较 HAT 和 TornadoVM 时,我将再次讨论这种相似性。
内存映射
这是 HAT 项目中我最喜欢的部分之一。HAT 定义了一个名为 iFaceMapper 的接口来表示数据。 数据实际上通过 Panama 内存段 API 存储在堆外,以便于 GPU 计算。
在我看来,对于 Java 等托管语言的 GPU 编程来说,因为 GC 会在需要时移动对象,与 GPU 的要求相冲突, 所以设计数据的表示方式是一大挑战,需要在性能、可移植性和易用性之间进行权衡。
为了解决这个问题,HAT 定义了一个能够访问和操作 Panama 内存段中数据的基本接口。 该接口可以扩展,使开发人员能够创建与 GPU 或其他硬件加速器兼容的自定义数据对象。
这个接口有很大的潜在价值。它不仅适用于 Babylon 和 HAT,还适用于 TornadoVM 等项目。
虽然 TornadoVM 目前提供了丰富的硬件加速器兼容数据类型,但缺少让用户自定义数据存储和表示方式的功能。 这个接口提供了一种非常有前景的集成方法,具有很强的灵活性和可控制性,未来也许能够用于改进 TornadoVM。
举个例子,我们可以这样在 HAT 中创建一个自定义数据对象来存储基于内存段的数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public interface MyCustomArray extends Buffer {
int length();
@BoundBy("length")
float data(long idx);
void data(long idx, float f);
// Define the schema
Schema<MyCustomArray> schema = Schema.of(MyCustomArray.class,
array -> array
.arrayLen("length")
.array("data"));
static MyCustomArray create(Accelerator accelerator, int length) {
return schema.allocate(accelerator, length);
}
}
然后,HAT OpenCL 编译器会生成如下的 C 结构:
1
2
3
4
typedef struct MyCustomArray_s {
int length;
float data[1];
} MyCustomArray_t;
虽然还需要写一些模板代码,但它可以用来定义与 GPU 兼容的自定义数据类型。这是不是很酷?
Accelerator 和 Compute Context
现在让我们来看看 API 的最后一部分,即 Accelerator 和 ComputeContext。 这两个对象用于定义要使用的后端(如 OpenCL、CUDA 等),以及我们要分载的 Kernel 列表。
1
2
3
4
var accelerator = new Accelerator(lookup, Backend.FIRST);
accelerator.compute(cc ->
MyClass.methodToOffload(cc, matrixA, matrixB, matrixC, size)
);
然后:
1
2
3
4
@CodeReflection
public static void methodToOffload(ComputeContext cc, MyCustomArray matrixA) {
cc.dispatchKernel(size, kc -> myGPUKernel(kc, data));
}
这里要注意,传递给 dispatchKernel 方法的第一个参数(本例中为 size)是要在 GPU 上部署的线程数。
示例:GPU 并行矩阵乘法
让我们将这些概念付诸实践,用 HAT 实现矩阵乘法。 矩阵乘法是现代计算负载(如深度学习、人工智能和 LLM 等)中使用的核心算法之一。 此外,这也是非常适合在 GPU 上进行加速的应用场景。
让我们从矩阵乘法的 Java 顺序实现开始:
1
2
3
4
5
6
7
8
9
10
11
12
13
private static void runSequential(F32Array matrixA, F32Array matrixB, F32Array matrixC, final int size) {
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
float sum = 0;
for (int k = 0; k < size; k++) {
float a = matrixA.array((long) i * size + k);
float b = matrixB.array((long) k * size + j);
sum += a * b;
}
matrixC.array((long) i * size + j, sum);
}
}
}
这展示了最标准的矩阵乘法(三层嵌套循环)。在 Babylon/HAT 中,我们可以这样将最外层的循环进行并行化处理:
1
2
3
4
5
6
7
8
9
10
11
12
@CodeReflection
public static void matrixMultiplyKernel(KernelContext kc, F32Array matrixA, F32Array matrixB, F32Array matrixC, int size) {
if (kc.x < kc.maxX) {
for (int j = 0; j < size; j++) {
float acc = 0;
for (int k = 0; k < size; k++) {
acc += (matrixA.array(kc.x * size + k) * matrixB.array(k * size + j));
}
matrixC.array(kc.x * size + j, acc);
}
}
}
这意味着,我们将在目标设备上部署与矩阵行数相等的线程数,使第一个循环并行运行。 每个线程将执行第二层和第三层循环(归约操作),对每列的值进行累加求和。
接下来,我们需要调度 Kernel。
1
2
3
4
5
6
@CodeReflection
public static void matrixMultiply(ComputeContext cc, F32Array matrixA, F32Array matrixB, F32Array matrixC, int size) {
cc.dispatchKernel(size,
kc -> matrixMultiplyKernel(kc, matrixA, matrixB, matrixC, size)
);
}
需要注意的是,该方法虽然不会在设备(GPU)上运行,但也包含 @CodeReflection 注解。 这是因为 HAT 可以在编译代码之前获取数据并推断类型,同时获取将要分载到设备上的方法的代码模型。 因此,该注解可以帮助 HAT 编译器和运行时处理数据,并生成正确的 OpenCL 和 CUDA PTX 代码。
您可以在此处查看完整示例:openjdk/babylon#276。
请注意,唯一会被分载到 GPU 的方法是 matrixMultiplyKernel,其余代码均在主机端(Java 平台)运行。
那么编译过程是如何完成的?哪些部分被分载?最终代码是什么样的?让我们深入探究这些问题。
Babylon/HAT 针对 GPU 的内部工作机制是什么样的?
截至 2025 年 2 月,HAT 支持 OpenCL 和 CUDA 后端,SPIR-V 后端也正在开发中 (有趣的是,SPIR-V 代码生成器库实际上是我们 TornadoVM 团队为 TornadoVM 开发的,我很高兴看到这样一个库在学术界之外得到应用)。
HAT 采用两阶段编译流程来生成 GPU 源码(如 OpenCL C 或 SPIR-V), 然后由相应的 GPU 驱动程序执行另一个编译阶段以获得最终的 GPU 二进制文件。 我们先来讨论一下 HAT 的两阶段编译流程。
下图抽象地展示了 Babylon/HAT 生成 GPU 代码时不同编译阶段的工作流程。
首先,正如前例所示,开发者使用 NDRange API 和 Accelerator Toolkit 来注释和识别要分载的代码。 由于方法具有 @CodeReflection 注解,javac 编译器会为其生成代码模型并存储在类文件中。
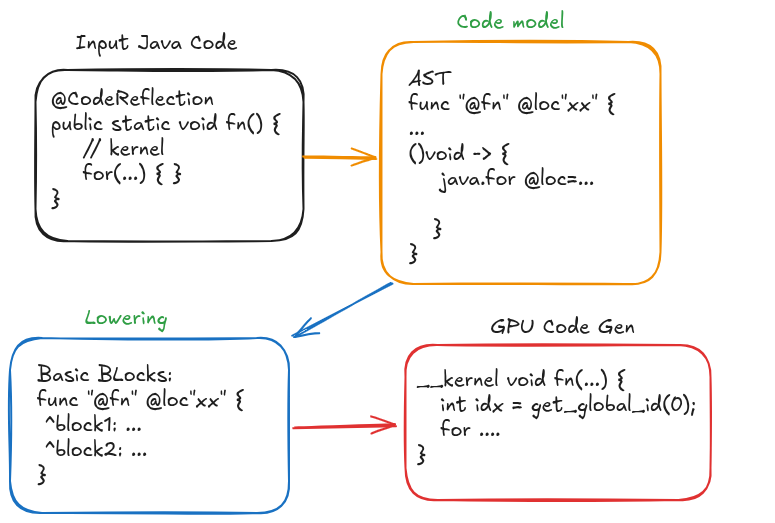
该代码模型与 AST(抽象语法树)非常接近,同时包含了类型与控制流信息。 此时 HAT 会执行降阶阶段(实际上是通过代码反射 API 调用降阶阶段),将原始代码模型转换为类似于 LLVM IR 的底层中间表示。
接着 HAT 会根据底层中间表示生成对应的 OpenCL C 代码(也可以生成 CUDA PTX——即CUDA程序的汇编代码,或 SPIR-V)。
生成 GPU 代码后,我们需要通过另一个编译器将其转换为 GPU 二进制文件, 这需要调用 GPU 驱动程序的对应函数来实现,例如 OpenCL 环境中对应的函数为 clBuildProgram。
需要注意的是,开发者可以直接基于代码模型生成 GPU 代码,无需经过降阶阶段。 对于一些目标代码类型,这可能是更简便的选择。但就生成 SPIR-V 或 CUDA PTX 而言,我觉得降阶阶段能为代码分载提供更合适的抽象层级。
想了解更多详情请查看源码:C99FFIBackend.java#L98-L102
好了,理论讲的够多了,让我们开始实战环节吧!
安装和配置用于 GPU 的 Babylon
安装需求
对于 Fedora(在 Fedora 41 上检查过):
1
sudo dnf install autoconf alsa-lib-devel cups-devel libXtst-devel libXt-devel libXrender-devel libXrandr-devel libXi-devel
对于 Ubuntu(在 Ubuntu 22.04.5 LTS 上检查过):
1
sudo apt-get install autoconf libasound2-dev libcups2-dev libfontconfig1-dev libx11-dev libxext-dev libxrender-dev libxrandr-dev libxtst-dev libxt-dev
安装支持 Babylon 代码反射的 OpenJDK 24
Babylon 和 HAT 正在持续开发中,因此构建方式将来可能发生变化。以下说明基于 Babylon(提交 ee3da03)。
1
2
3
4
# as in February 2025
sdk install java 23-open
sdk use java 23-open
配置 Babylon (Java JDK 和 Babylon Port)
首先,我们要从源代码构建 JVM 来配置 Babylon,然后我们将会使用生成的 JVM 在 GPU 上编译和运行 HAT 程序。
1
2
3
4
5
cd workdir
ROOT_BABYLON=`pwd`
git clone https://github.com/openjdk/babylon.git
bash configure --with-boot-jdk=${JAVA_HOME}
make images
现在我们得到了一个新的 OpenJDK 版本:
1
2
export JAVA_HOME=$ROOT_BABYLON/babylon/build/linux-x86_64-server-release/jdk
export PATH=$JAVA_HOME/bin:$PATH
配置 HAT
1
2
3
cd $ROOT_BABYLON/hat
source env.bash
java @bldr/args bld
在 GPU 上运行示例
例如,基于 OpenCL 后端运行 Mandelbrot:
1
java @bldr/hatrun ffi-opencl mandel
基于 CUDA PTX 后端运行 Mandelbrot:
1
java @bldr/hatrun ffi-ptx mandel
是不是很酷?现在让我们运行基准测试,并将其与 Java 和 TornadoVM 进行对比。
GPU 上矩阵乘法的性能评估
本节我们将对比基于 Babylon/HAT 的矩阵乘法的性能,并与 TornadoVM 进行对比。 测试平台采用的 CPU、GPU 以及其他软硬件配置如下表所示:
- CPU: 13th Gen Intel(R) Core(TM) i9-13900K
- GPU: RTX 4090
- NVIDIA-DRIVER: 550.107.02
- OS: Ubuntu 22.04.5 LTS
- Kernel: Linux 6.8.0-47
- RAM: 64GB
- CUDA: 12.1.r12.1
- GCC: 11.4.0
- TornadoVM: 1.0.10-dev (5da9549d1)
- JDK for TornadoVM: OpenJDK “21.0.4” 2024-07-16 LTS
- Babylon: cd3c7ce9c8a
- JDK for Babylon: openjdk 23.0.1
示例
让我们运行上一节中介绍过的矩阵乘法,并将其与 TornadoVM 进行对比。 基于 Babylon 的完整示例可以在这里查看:
https://github.com/jjfumero/babylon/tree/dev/examples/hat/examples/matmul
TornadoVM 版本可以在这里查看:
https://github.com/jjfumero/tornadovm-examples。
在这篇文章中,我不会解释如何使用 TornadoVM 进行编程。 如果您有兴趣,我推荐一篇之前的文章,其中我详细介绍了如何使用 TornadoVM 来加速不同的工作负载:https://jjfumero.github.io/posts/2024/23/tornadovm-programming-model.
后端
让我们评估一下 OpenCL C 和 PTX 后端。对于 OpenCL C,我使用 Intel 集成显卡。 虽然我的测试平台上可以采用 RTX 4090 来执行 OpenCL,但在我撰写本文时,Babylon 尚不支持多设备或设备切换功能。 为确保对比测试的公平性,在 TornadoVM 测试中我也选择使用集成 GPU。
相比之下,TornadoVM 有一个和有趣的功能:当存在多 GPU 时,TornadoVM 运行时系统会自动对设备进行排序, 并根据计算能力和待部署的线程数选择最佳设备。 因此在我的平台上,TornadoVM 默认选择 RTX 4090,在我看来这正是理想中的默认行为。
如何复现?
Babylon(OpenCL):
1
java @bldr/hatrun ffi-opencl matmul
Babylon(PTX):
1
java @bldr/hatrun ffi-ptx matmul
TornadoVM:
该实验取自 tornadovm-examples 项目。
注意,我们可以通过增加测试运行次数使其与 Babylon 实验的设置相匹配, 并且我们还移除了 2D 并行化,从而与 HAT/Babylon 示例完全一致:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
git diff
diff --git a/src/main/java/io/github/jjfumero/MatrixMultiplication.java b/src/main/java/io/github/jjfumero/MatrixMultiplication.java
index 81bf05c..13c5bb1 100644
--- a/src/main/java/io/github/jjfumero/MatrixMultiplication.java
+++ b/src/main/java/io/github/jjfumero/MatrixMultiplication.java
@@ -253,7 +253,7 @@ public class MatrixMultiplication {
*/
private static void mxmTornadoVM(Matrix2DFloat a, Matrix2DFloat b, Matrix2DFloat c, final int size) {
for (@Parallel int i = 0; i < size; i++) {
- for (@Parallel int j = 0; j < size; j++) {
+ for (int j = 0; j < size; j++) {
float sum = 0.0f;
for (int k = 0; k < size; k++) {
sum += a.get(i, k) * b.get(k, j);
@@ -277,7 +277,7 @@ public class MatrixMultiplication {
private static TornadoExecutionPlan createTornadoVMPlan(Matrix2DFloat a, Matrix2DFloat b, Matrix2DFloat c) {
TaskGraph taskGraph = new TaskGraph("mxm");
- taskGraph.transferToDevice(DataTransferMode.FIRST_EXECUTION, a, b) //
+ taskGraph.transferToDevice(DataTransferMode.EVERY_EXECUTION, a, b) //
.task("mxm", Multiplication::mxmTornadoVM, a, b, c, a.getNumRows()) //
.transferToHost(DataTransferMode.EVERY_EXECUTION, c);
TornadoExecutionPlan executionPlan = new TornadoExecutionPlan(taskGraph.snapshot());
@@ -455,7 +455,7 @@ public class MatrixMultiplication {
matrixA.initRandom();
matrixB.initRandom();
- final int RUNS = 10;
+ final int RUNS = 100;
// 6 implementations to compare
ArrayList<ArrayList<Long>> timers = IntStream.range(0, 6) //
这样来运行:
1
tornado -cp target/tornadovm-examples-1.0-SNAPSHOT.jar io.github.jjfumero.MatrixMultiplication onlyTornadoVM
如果我们在 TornadoVM 中安装了多个设备/后端,我们可以使用标志 -Dmxm.mxm.device=X:Y 来更改设备和运行时。 其中 X 和 Y 是必要的设备索引。您可以使用以下命令查看 TornadoVM 所有可用的设备:
1
tornado --devices
性能评估
Intel 集成 GPU 上的 OpenCL C
以下图表展示了所有测试在 100 次运行中的运行时间分布情况,具体包括:a) 使用 OpenCL 后端的 TornadoVM;b) 使用 OpenCL 后端调度 SPIR-V 代码的 TornadoVM;c) 通过 Level Zero API 调度 SPIR-V 代码的 TornadoVM。最后一个条形图展示了 Babylon 的运行时间分布。 所有测试均在 Intel 集成 GPU 上运行。 y 轴代表端到端总运行时间(单位为纳秒),数值越低越好。 每个测试的第一次运行时间都包括 JIT 编译时间。
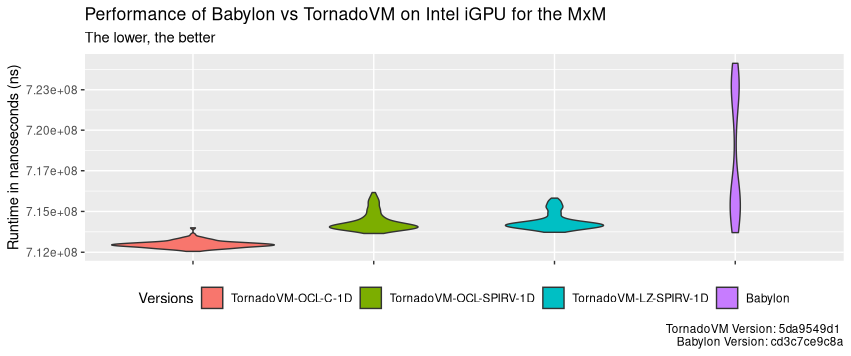
我们可以看到,即使包含 JIT 编译的时间,TornadoVM 的性能依然始终优于 Babylon。 TornadoVM 的性能也更加稳定,各次运行时间紧密围绕平均值分布。 Babylon 在同一 Intel 集成 GPU 上的性能波动范围较大,但最大与最小执行时间差仅为约 93 毫秒。
现在让我们来看看整体表现。让我们将这些实现方案分别与运行在 CPU 上的 Java 原生代码及结合了 Java Stream 的 Java Vector API(当前 Java 在 CPU 端的最高性能实现)进行对比。 下面的性能图展示了在峰值性能(预热后)下各个实现方案与 Java 顺序执行相比的速度提升:
下面的性能图显示了在峰值性能(预热后)下与 Java 连续运行相比的速度提升,具体包括 a) CPU 上的 Java Vector API;b) Intel 集成 GPU 上使用 OpenCL C 的 TornadoVM(2D kernel);c) 使用 OpenCL C 的 TornadoVM(1D kernel);d) Babylon/HAT。
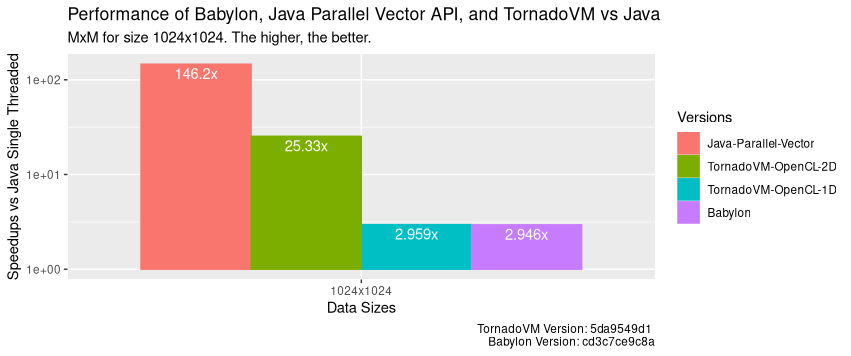
可以看到,对于该矩阵乘法应用,在集成 GPU 上运行性能并不比 CPU 上运行的并行 Java Vector API 更好。 记住!除非您有性能强大的加速器,否则不要低估 CPU 的性能!
如果我们加入 NVIDIA 4090 GPU 进行对比,那么正如我在最近的一篇技术文章介绍的那样,基于 OpenCL 后端的 TornadoVM 相比 Java 实现性能可提升 2500 倍!
CUDA PTX 后端
那么在 NVIDIA 4090 GPU 上运行的 PTX 后端又如何呢?下面的性能图显示了 Java 顺序版本、并行 Java Vector API 版本、PTX 后端的 TornadoVM 1D、TornadoVM 2D 版本和 Babylon 的 100 次运行时间分布(越低越好)。
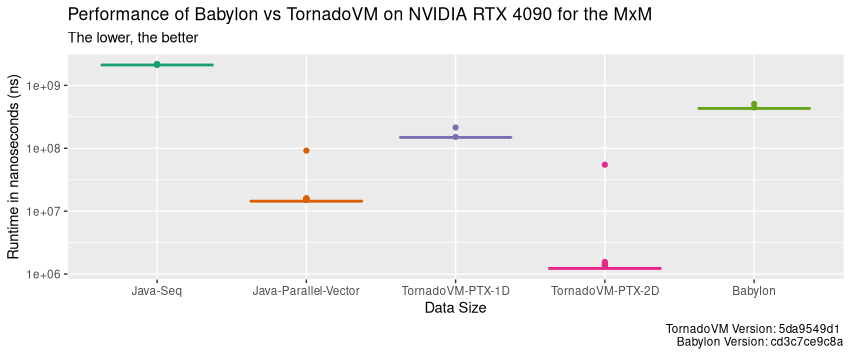
途中圆点表示第一次运行,其中 TornadoVM 和 Babylon 包含执行 JIT 编译时间。 我们可以看到,即使在包含 JIT 编译与执行的首轮运行中,TornadoVM 的运行速度依然显著快于 Babylon。 与 Babylon 相比,TornadoVM 1D 版本快 2.3 倍,2D 版本快 9.3 倍。
通过对比 Babylon、TornadoVM 1D 与 Java Vector API 时可见,前两者比 CPU 并行实现的效率反而更低。 当采用独立显卡时,必须综合考虑分载的开销, 其中包括主 CPU 和 GPU 之间数据迁移的成本,以及在设备上执行的并发/并行操作的数量。 对于当前的矩阵乘法应用来说,1D 方案的硬件利用率很低。
如果您想深入对比分析 Java Vector API 与 TornadoVM,我推荐您阅读以下文章: https://jjfumero.github.io/posts/2024/12/17/tornadovm-vs-opencl。
通过观察 PTX 后端与 Java 顺序方案的速度对比:
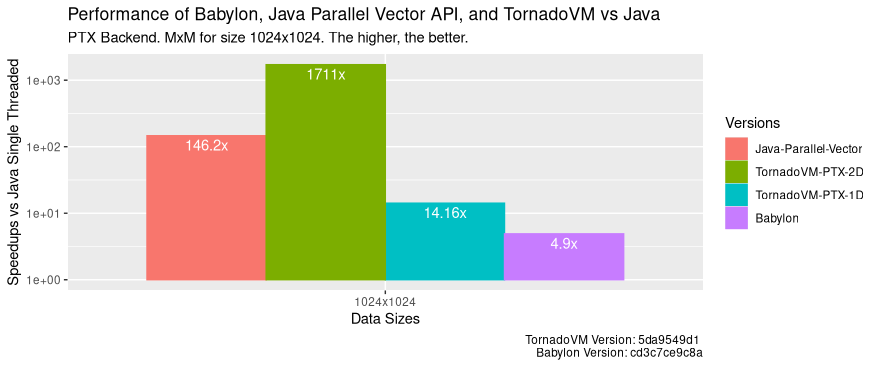
我们可以看到,在相同的 GPU 下,TornadoVM 的速度是 Java 顺序方案的 1700 倍,比 CPU 执行速度快 11 倍,比 Babylon/HAT 快 346 倍。
这是否意味着 TornadoVM 总是比 Babylon/HAT 快? 其实不一定。对于某些应用来说,TornadoVM 可能更快,但对于另一些应用可能更慢。 正如我要在下一节详细介绍的那样,TornadoVM 有一个 JIT 编译器和一个优化器,这可以在某些应用程序中带来性能优势。
HAT vs TornadoVM:差异和限制
让我们来谈谈 Babylon 和 TornadoVM 目前的局限性。 请记住,这两个项目都在积极开发中,我现在(2025 年 2 月)所描述的局限性可能会在不久的将来被解决/克服。
目前 Babylon/Hat 相对于 TornadoVM 的局限性
显然,Babylon 和 HAT 的核心目标是提供一个便于对 Java 代码进行操作和转换的接口, 所以它主要关注的是编译和运行代码的最小运行时支持(例如数据处理和数据表示)。
相比之下,TornadoVM 提供了更完整的解决方案。其支持范围不仅限于 GPU,还涵盖各类现代硬件加速器。 为此,TornadoVM 提供了一个更加复杂的工程框架,为不同架构实现自适应编译器优化, 并提供了专门的代码优化器以及针对不同架构和供应商的优化运行时系统。
下面我们进行详细的解析:
运行时限制
目前 Babylon HAT 的运行时功能很有限。 与 TornadoVM 相比,HAT 缺少动态多设备选择功能(比如多个 GPU)和动态任务迁移能力。 它的设备始终是静态分配的,导致难以适应运行时的环境变化。 此外,它也不支持数据范围的拷贝操作,这限制了自动数据管理能力(例如无法实现自动批处理功能)。
硬件支持和代码生成
目前 Babylon HAT 仅支持对于 GPU 的代码生成和运行时调度。 相对于支持来自多家供应商(Intel、NVIDIA 和 AMD)的 GPU、CPU、FPGA 甚至 RISC-V 加速器的 TornadoVM 相比, Babylon 支持的硬件明显少的多。 虽然未来 Babylon 可能会支持更多设备,但当前的限制仍制约了其适用场景。 此外,缺少代码优化器可能会影响其在专用硬件加速器的性能潜力 [4]。
编译时优化
目前 Babylon 尚未提供优化编译器,而 TornadoVM 扩展了当下最先进的开源 Graal JIT 编译器, 为 GPU、FPGA 和多核 CPU 提供了新的编译器优化管道,实现了调整循环顺序、自动使用快速 intrinsic、自动使用本地/共享内存等优化。
并行性和 API 复杂性
目前 Babylon HAT 尚未原生支持 2D 和 3D 并行计算(或 2D 和 3D 范围)。 虽然这个功能相对简单,未来应该会实现,但目前的缺失限制了对多维问题的高效并行化。
HAT API 采用 Range 编程模型,这就要求开发者必须掌握 CUDA、OpenCL 或 oneAPI 等 GPU 编程模型的专业知识。 具备此类背景的开发者能快速上手,而缺乏相关经验的开发者则可能面临陡峭的学习曲线。
这与 TornadoVM 的双重 API 设计形成鲜明对比: 它既为新手开发者提供基于注解的高级 API,也为专业开发者提供类似 Babylon Range API 的低级 Kernel API。 我认为这种双重策略能够照顾到更多开发者。
目前 TornadoVM 相对于 Babylon/HAT 的局限性
无论如何,TornadoVM 并不完美。它还在持续开发中,每个新版本都在进步。
支持自定义数据类型
TornadoVM 的主要局限性在于缺乏对 Java 中自定义与硬件加速器兼容的数据类型的支持。
Babylon 的 iFaceMapper 能够用于定义和处理兼容硬件加速器和 Java 运行时的高效数据结构, 是非常有前景的解决方案。
新 API 和数据类型
这一情况同样适用于 Babylon/HAT,但由于我参与 TornadoVM 项目更深,所以在此处具体阐述。
虽然提供 API 和新类型对实现高性能开发至关重要,但开发者不得不为此学习新 API。 在我看来,若这些新接口能够成为 JDK 的一部分,那么普及此类技术将更为顺畅。
结构化编程语言的代码生成
TornadoVM 的代码生成过程较为复杂,特别是对于 OpenCL C 后端。 从底层细节来看,TornadoVM 从 Graal IR(一种非结构化流 IR [5])的底层生成代码。 这里最大的挑战是如何从非结构化流程图生成结构化的 OpenCL C Kernel,这导致有时很难生成正确的代码。
对 TornadoVM 而言,更理想且更简单的目标是 CUDA PTX 和 SPIR-V,而非 OpenCL C,但并非所有供应商(例如 NVIDIA)都允许通过 OpenCL 运行 SPIR-V。
由于 Babylon 是从近似 AST 的形式开始生成,因此更容易生成正确的 OpenCL C 代码。
维护支持
TornadoVM 支持更多后端和设备类型,这带来了更高的维护成本。
对于像 TornadoVM 这样的小团队来说,始终要在开发新功能与保持 TornadoVM 适用于所有可能的设备、架构和操作系统之间进行权衡。 这虽然不是设计缺陷,但它是客观存在的局限性,不容忽视。
我希望就此展开讨论。您是否发现了其他局限性?欢迎在评论区分享您的见解。
总结和最终想法
Babylon 增强了反射 API,使开发者能够在运行时直接操作代码模型。 通过增强的反射 API 以及 HAT 子项目,Babylon 拥有了动态生成 GPU 代码的能力,从而提供了一种有趣的 Java GPU 编程方案。
本文简要介绍了 Babylon 项目及其 HAT 子项目实现的 GPU 编程方案,并将其与 TornadoVM 进行了对比, 分析了它们性能的差别、相似之处与不同之处。 这些分析都来自于一位过去 12 年(时间过得真快!)一直在参与 Java GPU 编程领域的实践者。
我期待看到 HAT 未来能成为 OpenJDK 的一个 incubator 项目,通过它增强 Java 平台, 使 Java 开发者不仅能利用现代 GPU,还能使用其他新型加速器(例如 NPU)。
在我看来,Babylon/HAT 向着统一和整合 API 迈出了重要一步, 它帮助硬件供应商和软件实现者(如 TornadoVM)在保证性能的同时又能与 Java 生态紧密结合。
在这方面,我认为 HAT 借鉴了 TornadoVM、Aparapi 等项目的理念和研究成果。 比如说,正如 HAT 项目首席软件架构师、Aparapi 创始人 Gary Frost 所承认的, HAT Accelerator 和 Compute-Context API 的设计灵感就源自 TornadoVM API。 此外,我也看到了从 Aparapi 项目借鉴而来的一些想法。
正如我前面提到的,TorandoVM 不仅是一个范例,也是技术的推动者, 它让 HAT 开发人员能够使用我们为 TornadoVM 实现 SPIR-V 后端而开发的 Java 库编写 SPIR-V 后端。
讨论
如果您对此有兴趣,让我们在这里继续讨论:jjfumero/jjfumero.github.io#14
链接
[1] https://mail.openjdk.org/pipermail/discuss/2023-September/006226.html
[2] https://openjdk.org/projects/babylon/articles/code-models
[3] https://openjdk.org/projects/babylon/articles/linq
[4] https://jjfumero.github.io/posts/2024/12/17/tornadovm-vs-opencl
[5] https://dl.acm.org/doi/pdf/10.1145/2816707.2816715