[翻译] 更快的字符集解码
Faster Charset Decoding 翻译
原文链接:Faster Charset Decoding - Claes Redestad’s blog
最近,我对 OpenJDK 进行了一些小改进,以解决如何将 byte[] 转换为 String 的问题 —— 包括删除 StringCoding.Result 结构和减少一些遗留的 CharsetDecoder 开销。
在进行这方面实验时,我偶然发现了一个性能差异:new String(bytes, charset) 通常比使用 InputStreamReader 创建同一字符串快很多倍,差距远大于直觉上的合理范围。
通过分析原因后尽最大努力优化,我可以带来一些相当显著的改进。
太长不看:通过重用用于支持 JEP 254: Compact Strings 的一些 intrinsic 方法, 我们能够让与 ASCII 兼容的 CharsetDecoders 在微基准测试中得到高达 10 倍的速度提升。 这些优化应该在 JDK 17 中实现。
紧凑字符串
为了深入理解我所做的工作,我们必须追溯到几年前在 JDK 9 中(重新)引入紧凑字符串的工作。
在 JDK 8 的 String 中,其内容存放于一个 char[] 中,这种实现方式简单明了。 但是 Java 中的 char 是 16 位的原始类型,其值(大致地)映射至 UTF-16。 在很多软件中,很多——甚至大部分——字符串都只是用最低的 7 位(ASCII)或者 8 位(ISO-8859-1), 因此每存储一个字符大概会浪费一个字节。
使得,有些地区的常用码点在 UTF-16 中需要超过 8 位甚至 16 位存储, 但经验中,几乎任何地区的应用程序里都有大量仅限于 ASCII 的字符串。 以更紧凑的形式存储这些数据将非常可观减少内存浪费,特别是对于那些每个字符仍需两个或更多字节存储的字符串来说, 它(几乎)不需要成本。
在以前我们考虑过并实现了更节约空间的表示法。JDK 6 中有 -XX:+UseCompressedStrings, 它会改变 String 的实现,透明地使用 byte[] 或 char[]。 在我开始工作于 OpenJDK 之上前,该实现已经被删除,我被告知它是一个维护噩梦, 而且当运行具有大量非 ASCII 字符串的应用程序时,这会严重降低性能。
在 JDK 9 中,JEP 254:紧凑字符串进行了新的尝试。现在字符串始终由 byte[] 表示, 而不需要在 byte[] 与 char[] 之间来回切换。可以使用一个简单的方案将 char 映射至 byte[] 中:
- 如果所有字符都可以用 ISO-8859-1 编码表示:“压缩”它们,每个字符使用 1 字节表示
- 否则将所有字符拆分为两个字节相邻的存储。依然有效地使用 UTF-16 编码
添加一些逻辑进行双向映射,我们就完成了!
嗯,虽然减少内存占用本身很重要,但您也需要恰当的性能。
如果对符合 ISO-8859-1 的字符串进行加速需要在用 UTF-16 编码的字符串上付出巨大代价,这就不好了。 为了缓解这种忧虑,JEP 254 花费了巨大的努力。integration lists 中列出了 9 名合作者与 12 名审查者, 我相信还有更多的工程师参与了 QA 等工作。
Intrinsically fast
优化性能的其中一种方式是实现类似将 char[] 压缩为 byte[] 和将 byte[] 膨胀为 char[] 的 intrinsic 方法, 这在许多情况下都优于 JDK 8 基线。
JDK 术语中的 Intrinsic 方法是一种 Java 方法,JVM(像 OpenJDK HotSpot)可以用高度优化的手工实现的方法替代这些方法。 这样的手工优化需要做大量的工作,但可以确保 JVM 在一些非常具体且对性能高度敏感的情况下做出正确的事情。
对于 JEP 254 中实现的方法,其主要优势是允许专门使用现代的 SIMD 指令。 SIMD 代表单指令、多数据、一次性描述对多位数据进行操作的硬件指令。 例如,Intel 的 AVX2 扩展可以一次性操作 256 位数据。在某些情况下, 使用此类指令能够大大提高速度。
Deep Dive: new String(bytes, US_ASCII)
要查看我们可能正在运行哪些 SIMD 指令,让我们看一个更简单的场景。
在最近 JDK 上的 new String(byte[], Charset),当 Charset 为 US_ASCII 时:
1
2
3
4
5
6
7
8
9
10
11
12
13
if (COMPACT_STRINGS && !StringCoding.hasNegatives(bytes, offset, length)) {
this.value = Arrays.copyOfRange(bytes, offset, offset + length);
this.coder = LATIN1;
} else {
byte[] dst = new byte[length << 1];
int dp = 0;
while (dp < length) {
int b = bytes[offset++];
StringUTF16.putChar(dst, dp++, (b >= 0) ? (char) b : REPL);
}
this.value = dst;
this.coder = UTF16;
}
if 分支检查 CompactString 是否启用,然后调用 StringCoding.hasNegatives :
1
2
3
4
5
6
7
8
9
@IntrinsicCandidate
public static boolean hasNegatives(byte[] ba, int off, int len) {
for (int i = off; i < off + len; i++) {
if (ba[i] < 0) {
return true;
}
}
return false;
}
这是一个简单的检查,如果输入数组中的任何值为负,则返回 true。如果没有负字节,则输入的字符都是 ASCII, 我们可以继续将输入复制到 String 的内部 byte[] 中。
Experimental setup
在 readStringDirect JMH 微基准测试中,我们可以找到一个简单但有趣的场景:
1
2
3
4
@Benchmark
public String readStringDirect() throws Exception {
return new String(bytes, cs);
}
为了放大上面详述过的 US-ASCII 快速路径,我使用 -p charsetName=US-ASCII -p length=4096 运行该基准测试。
我的实验装置是一个有些老旧的基于 Haswell 的 Linux 工作站。对于 Mac 或 Windows, 可能需要对指令进行调整,而且在更新或更旧的硬件上,结果可能有所不同。
我还确保我的 JDK 预备好了 hsdis 共享库,它允许使用 -XX:+PrintAssembly 反编译编译后的方法。 (虽然它是 OpenJDK 的一部分,但是因为各种许可原因,无法分发 hsdis 的构建。这里是 Gunnar Morling 编写的一个很棒的指南, 介绍了如果找不到二进制文件,应该如何自己构建它。)
然后我用 -prof perfasm 运行微基准测试。这个优秀的内置分析器使用 Linux perf 分析器以及通过 -XX:+PrintAssembly 收集的数据, 以非常细粒度的信息描述了微基准测试中执行的热点代码区域。
Experimental Results
扫描分析器输出中热点代码片段,这是其中非常突出的一个部分:
1
2
3
4
5
6
7
8
│ 0x00007fef79146223: mov $0x80808080,%ebx
0.02% │ 0x00007fef79146228: vmovd %ebx,%xmm0
│ 0x00007fef7914622c: vpbroadcastd %xmm0,%ymm0
0.21% │↗ 0x00007fef79146231: vmovdqu (%rsi,%rcx,1),%ymm1
13.16% ││ 0x00007fef79146236: vptest %ymm0,%ymm1
11.34% ││ 0x00007fef7914623b: jne 0x00007fef791462a3
1.63% ││ 0x00007fef7914623d: add $0x20,%rcx
│╰ 0x00007fef79146241: jne 0x00007fef79146231
是的,x86 汇编!让我们尝试分解它……
第一列表示执行每条命令所花费的相对时间。这些值可能有一点偏差或抖动,但单条指令超过 10% 是罕见的。
第二列中的字符画箭头表示控制流变化——例如跳转到循环的开头。第三列列出了地址。其余的是每个地址反汇编出的 x86 汇编代码。
前三条指令准备了 256 位 ymm0 向量寄存器,让其容纳值 0x80——重复 32 次。 这是通过将 0x80808080 加载到 xmm0 寄存器中,然后使用 vpbroadcastd 将其散布到 ymm0 的所有 32 位段中完成的。
为什么是 0x80?因为 0x80 是一个设置了最高位的字节。在 Java 中,设置了最高位的字节将为负数。 因此,ymm0 中的值可以用作掩码,用于检测另一个 ymm 寄存器中的任意字节是否为负。
这正是在下面循环中完成的:
vmovdqu (%rsi,%rcx,1),%ymm1)将 32 个字节从输入数组加载到ymm寄存器中。vptest %ymm0,%ymm1在ymm0中的掩码和我们刚刚读取的 32 字节之间执行逻辑与操作。- 如果任意字节为负,则下一条指令
jne跳出循环。 - 否则,在输入数组中跳过前 32 个字符并重复,直到
rcx为 0。
这张图片中没有看到的是确保 rcx 中的值为 32 倍数的设置,以及对最多 31 个尾随字节的处理。
好的,我们可以看到我们运行的代码是如何利用 AVX2 指令的。但是这对微基准的性能有多大贡献呢?
Benchmarking the effect of the intrinsic
刚好,我们可以关闭 intrinsic 函数。这让我们能够对比在没有 C2 手工实现的 intrinsic 的情况下的性能。 (一个问题是需要弄清楚 HotSpot 将这些 intrinsic 函数叫做什么;我不得不使用 grep 查询 OpenJDK 源代码,发现它的标识是 _hasNegatives):
1
2
3
4
5
6
Benchmark Score Error Units
readStringDirect 1005.956 ± 36.044 ns/op
-XX:+UnlockDiagnosticVMOptions -XX:DisableIntrinsic=_hasNegatives
readStringDirect 4296.533 ± 870.060 ns/op
在这个简单的基准测试中,hasNegatives 的 intrinsic 向量化让速度提高了三倍以上。太酷了!
Enter the InputStreamReader
None of the above was fresh in my memory until recently. I wasn’t involved in JEP 254, unless “enthusiastic onlooker” counts. But as it happened, I recently started doing some related experiments to assess performance overhead of InputStreamReader. Motivated by a sneaking suspicion after seeing a bit too much of it in an application profile.
I conjured up something along these lines:
1
2
3
4
5
6
@Benchmark
public String readStringReader() throws Exception {
int len = new InputStreamReader(
new ByteArrayInputStream(bytes), cs).read(chars);
return new String(chars, 0, len);
}
这是一个简单的人造微基准,故意避免了 I/O 操作。因为它有些脱离现实,因为 InputStream 的重点通常是在处理 I/O 操作上, 但是测量非 I/O 开销仍然很有趣。
我还配置了我上面实验中使用的 readStringDirect 基准作为对此性能评估的基准。 我预计中 readStringReader 将比 readStringDirect 慢几倍: InputStreamReader 需要先将读取的字节解码为字符,然后在字符串构造器中将它们压缩回字节。 但我仍然对实测出 12 倍差距感到惊讶:
1
2
3
Benchmark Score Error Units
readStringDirect 1005.956 ± 36.044 ns/op
readStringReader 12466.702 ± 747.116 ns/op
Analysis
后来的一些实验表明,对于较小的输入,readStringReader 有明显的恒定开销。 这主要在于需要分配一个 8Kb byte[] 作为内部缓存区。但同样很明显的是,InputStreamReader 的伸缩性也很差:
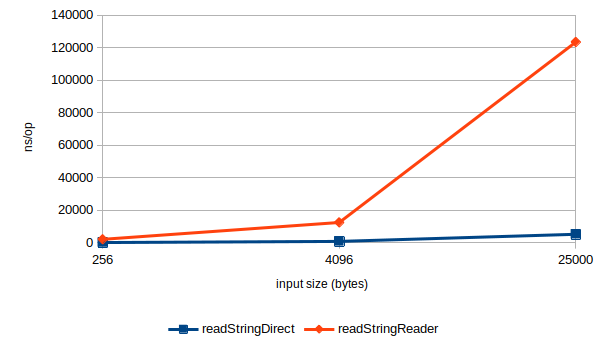
当输入大小从 4096 变成 25000 时(倍率为 6.1),readStringDirect 基准测试的开销将会上升到 6.5 倍。 这和我的预期时一致的:基本是线性的,但也有一些超出各种缓存阈值带来的小幅度超线性效果。 但是,readStringReader 的开销上升到了 10 倍。
深入分析数据,很明显能发现 readStringReader 的大部分时间都用在 US_ASCII$Decoder.decodeArrayLoop 中将 byte[] 逐个复制到 char[] 上:
1
2
3
4
5
6
7
8
9
10
11
while (sp < sl) {
byte b = sa[sp];
if (b >= 0) {
if (dp >= dl)
return CoderResult.OVERFLOW;
da[dp++] = (char)b;
sp++;
continue;
}
return CoderResult.malformedForLength(1);
}
在热路径上有多个分支是一个危险信号——这可能是超线性开销增加的原因。
Reuseable intrinsics
事后看来,解决方案是显而易见的:从 byte[] 复制到 char[] 是在 JEP 254 中必须花费大量精力优化以保证良好性能的原因之一。 一旦我意识到它实际上是可行的,重用那些 intrinsic 似乎是一件轻而易举的事情。
为了保持整洁并尽量减少实现细节的泄露,我最终发布了一个 PR, 它只公开了两个 java.lang 的内部方法以供 sun.nio.cs 中的解码器使用:
decodeASCII,它接受一个输入byte[]和一个输出char[],尽可能地进行解码。 为了提高效率和简化,它使用String中新的 package private 方法实现:1 2 3 4 5 6 7 8 9 10 11 12 13
static int decodeASCII(byte[] sa, int sp, char[] da, int dp, int len) { if (!StringCoding.hasNegatives(sa, sp, len)) { StringLatin1.inflate(sa, sp, da, dp, len); return len; } else { int start = sp; int end = sp + len; while (sp < end && sa[sp] >= 0) { da[dp++] = (char) sa[sp++]; } return sp - start; } }
inflateBytesToChars,它公开了 intrinsic 方法StringLatin1.inflate,特别是用于ISO_8859_1$Decoder。
US_ASCII$Decoder.decodeArrayLoop 中的 while 循环可以这样重写:
1
2
3
4
5
6
7
8
9
10
11
12
int n = JLA.decodeASCII(sa, sp, da, dp, Math.min(sl - sp, dl - dp));
sp += n;
dp += n;
src.position(sp - soff);
dst.position(dp - doff);
if (sp < sl) {
if (dp >= dl) {
return CoderResult.OVERFLOW;
}
return CoderResult.malformedForLength(1);
}
return CoderResult.UNDERFLOW;
语义相同,但将大部分工作委托给 decodeASCII 方法,由于 SIMD intrinsic,这应该能解锁一些速度提升。
Results
使用优化版本绘制同一个图形,将得到完全不同的图像:
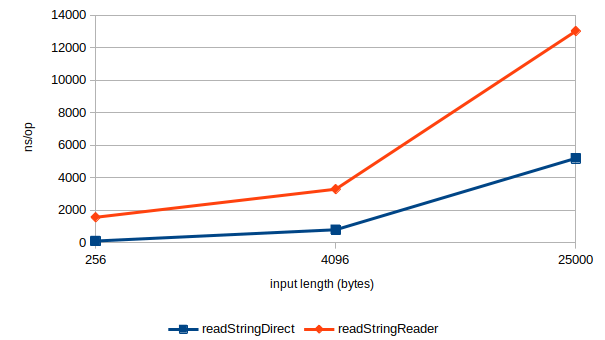
考虑到 InputStreamReader 的恒定开销,readStringReader 现在落后于 readStringDirect 大概 2.2 倍, 并显现出类似的倍率。
在长度为 25000 的输入点中,优化让对于 US-ASCII 的速度提高至接近原先的十倍。 在前面提到的 PR 中(现已合并),我试图改进每一个适用的内置 CharsetDecoder。 也许工作比听起来要少,因为他们中的很多继承自一些可以优化的基类。 最终结果是,很多字符集解码器在读取 ASCII 时可以采用这种内在化的快速路径。
之前:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Benchmark (charsetName) (length) Cnt Score Error Units
readStringReader US-ASCII 256 10 2085.399 ± 66.522 ns/op
readStringReader US-ASCII 4096 10 12466.702 ± 747.116 ns/op
readStringReader US-ASCII 25000 10 123508.987 ± 3583.345 ns/op
readStringReader ISO-8859-1 256 10 1894.185 ± 51.772 ns/op
readStringReader ISO-8859-1 4096 10 8117.404 ± 594.708 ns/op
readStringReader ISO-8859-1 25000 10 99409.792 ± 28308.936 ns/op
readStringReader UTF-8 256 10 2090.337 ± 56.500 ns/op
readStringReader UTF-8 4096 10 11698.221 ± 898.910 ns/op
readStringReader UTF-8 25000 10 66568.987 ± 4204.361 ns/op
readStringReader ISO-8859-6 256 10 3061.130 ± 120.132 ns/op
readStringReader ISO-8859-6 4096 10 24623.494 ± 1916.362 ns/op
readStringReader ISO-8859-6 25000 10 139138.140 ± 7109.636 ns/op
readStringReader MS932 256 10 2612.535 ± 98.638 ns/op
readStringReader MS932 4096 10 18843.438 ± 1767.822 ns/op
readStringReader MS932 25000 10 119923.997 ± 18560.065 ns/op
之后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Benchmark (charsetName) (length) Cnt Score Error Units
readStringReader US-ASCII 256 10 1556.588 ± 37.083 ns/op
readStringReader US-ASCII 4096 10 3290.627 ± 125.327 ns/op
readStringReader US-ASCII 25000 10 13118.794 ± 597.086 ns/op
readStringReader ISO-8859-1 256 10 1525.460 ± 36.510 ns/op
readStringReader ISO-8859-1 4096 10 3051.887 ± 113.036 ns/op
readStringReader ISO-8859-1 25000 10 11401.228 ± 563.124 ns/op
readStringReader UTF-8 256 10 1596.878 ± 43.824 ns/op
readStringReader UTF-8 4096 10 3349.961 ± 119.278 ns/op
readStringReader UTF-8 25000 10 13273.403 ± 591.600 ns/op
readStringReader ISO-8859-6 256 10 1602.328 ± 44.092 ns/op
readStringReader ISO-8859-6 4096 10 3403.312 ± 107.516 ns/op
readStringReader ISO-8859-6 25000 10 13163.468 ± 709.642 ns/op
readStringReader MS932 256 10 1602.837 ± 32.021 ns/op
readStringReader MS932 4096 10 3379.439 ± 87.716 ns/op
readStringReader MS932 25000 10 13376.980 ± 669.983 ns/op
请注意,UTF-8——也许是现在使用的最广泛的编码之一——在其解码器中已经有了 ASCII 快速路径。 这种快速路径避免了一些分支,并且似乎比其他字符集解码器伸缩性更好: 在扣除恒定开销后,从 4096 到 25000 个输入的开销倍率为 6.5 倍。 但即使是 UTF-8 通过重用 intrinsic 函数在我的系统上也能看到显著改进。 25000 个字节输入的情况下几乎提高了四倍。
最后,在这个特定的微型计算机上,对于小输入的性能提高至大概原先的 1.3 倍, 对于大输入提高至 10 倍以上。
我添加了许多其他微基准,以探索在输入中添加非 ASCII 字符时微基准的行为,包括添加在开头、结尾以及混合至输入中: 之前/之后。 *Reader 微基准的行为一般近似于 *Direct,但也有一些例外, 一些 Reader 变体由于以 8Kb 块处理输入,其实际性能变得更好。
可能有一些方法可以进一步改进代码,尤其是在处理混合输入时: 当解码为 char[] 时,将 String.decodeASCII 转换为结合 hasNegatives + inflate 的 intrinsic 可能是有意义的, 因为当我们发现一个负字节时,我们实际上不必退出并重新开始。但这一改进已经取得了很大的进步, 因此我拒绝了追求额外收益的诱惑。至少在尘埃落定之前。
Real world implications?
一位用户找到我,希望在他们的一个应用程序中对此进行测试,因为他们在分析中看到了 decodeArrayLoop 的大量使用。 在从源代码构建 OpenJDK PR 后,他们甚至可以在集成之前测试补丁——并报告总 CPU 使用量减少了大概 15-25%!
但是……事实证明,I/O 通常是他们的瓶颈。因此对 CPU 的节约非常显著,但在他们的很多测试中,这并没有转化为吞吐量的提升。 YMMV: Not all I/O is shaped the same way, and the optimization could have positive effects on latency.
最后,我认为这个问题中的用户似乎对 CPU 使用的减少很满意,即使这没有大大提高他们的吞吐量。 不出意外的话,这将转化为对耗电量和成本的节约。
Acknowledgements
I’d like to especially thank Tobias Hartmann for helping out with many of the questions I had when writing this post. I also owe a debt of gratitude to him alongside Vivek Deshpande, Vladimir Kozlov, and Sandhya Viswanathan for their excellent work on these HotSpot intrinsics that I here was merely able to leverage in a few new places. Also thanks to Alan Bateman and Naoto Sato for reviewing, discussing and helping get the PR integrated, and to David Delabassee for a lot of editorial suggestions.
Appendix: Internals of a C2 intrinsic
I was curious to find out if my reading of the disassembly made sense, but couldn’t find my way around. The C2 code is tricky to find your way around, mainly due heavy reliance on code generation, but Tobias Hartmann - who I believe wrote much of this particular intrinsic - was kind enough to point me to the right place: C2_MacroAssembler::has_negatives.
This is the routine that emits x86 assembler custom-built to execute this particular piece of Java code as quickly as possible on the hardware at hand. If you studied that code you’d find the macro assembler used to emit the hot piece code I found when profiling above at line 3408:
1
2
3
4
5
6
7
8
9
10
movl(tmp1, 0x80808080); // create mask to test for Unicode chars in vector
movdl(vec2, tmp1);
vpbroadcastd(vec2, vec2, Assembler::AVX_256bit);
bind(COMPARE_WIDE_VECTORS);
vmovdqu(vec1, Address(ary1, len, Address::times_1));
vptest(vec1, vec2);
jccb(Assembler::notZero, TRUE_LABEL);
addptr(len, 32);
jcc(Assembler::notZero, COMPARE_WIDE_VECTORS);
Not without its’ quirks, but a bit more higher level and somewhat readable.