[翻译] Arrays of Wisdom of the Ancients
原文链接:Arrays of Wisdom of the Ancients
Aleksey Shipilёv, @shipilev, aleksey@shipilev.net
感谢 Claes Redestad, Brian Goetz, Ilya Teterin, Yurii Lahodiuk, Gleb Smirnov, Tim Ellison, Stuart Marks, Marshall Pierce, Fabian Lange 和其他人的评论与建议!
简介
Java 语言和 JDK 类库有两种不同但相关的方式对元素进行分组:数组和集合。使用其中任意一个都有利有弊,因此在实际程序中都很普遍。
为了帮助在两者之间进行转换,有一些标准方法可以引用数组让其表现为集合(例如 Arrays.asList),
以及从集合复制到数组(例如几个 Collection.toArray 方法)。
在这篇文章中,我们将尝试回答一个有争议的问题:哪种 toArray 转换模式更快?
这篇文章使用 JMH 作为研究用的“坩埚”。 如果您还没有了解过它,并且还没有浏览过 JMH 的示例, 我建议您在阅读本文的其余部分之前先了解它,以获得最佳体验。 一些 x86 汇编知识也很有用,虽然它们不是必要的。
API 设计
在集合上盲目地调用 toArray 和遵循通过工具或在互联网上搜索找到的建议似乎是很自然的。
但是,如果我们查看 Collection.toArray 的一系列方法,我们可以看到两种不同的方法:
public interface Collection<E> extends Iterable<E> {
/**
* Returns an array containing all of the elements in this collection.
*
* ...
*
* @return an array containing all of the elements in this collection
*/
Object[] toArray();
/**
* Returns an array containing all of the elements in this collection;
* the runtime type of the returned array is that of the specified array.
* If the collection fits in the specified array, it is returned therein.
* Otherwise, a new array is allocated with the runtime type of the
* specified array and the size of this collection.
*
* ...
*
* @param <T> the runtime type of the array to contain the collection
* @param a the array into which the elements of this collection are to be
* stored, if it is big enough; otherwise, a new array of the same
* runtime type is allocated for this purpose.
* @return an array containing all of the elements in this collection
* @throws ArrayStoreException if the runtime type of the specified array
* is not a supertype of the runtime type of every element in
* this collection
*/
<T> T[] toArray(T[] a);
这些方法表现出微妙的不同,这是有原因的。泛型的类型擦除带来的阻抗迫使我们要使用实际参数精准地拼写出目标数组类型。
请注意,简单地将 toArray() 返回的 Object[] 强制转换为 ConcreteType[] 是不可行的,
因为运行时必须保持类型安全——尝试这样转换数组会导致 ClassCastException。
接受数组的方法还可以通过预分配的数组防止结果。事实上,前辈的经验可能会告诉我们,为了得到最佳性能,我们最好提供预先确定好长度的数组(甚至可能长度为零!)。 IntelliJ IDEA 15 建议我们传递预先确定好长度的数组,而不是懒惰地传递传递长度为零的数组。 它接着解释说,库必须通过反射调用来分配给定运行时类型的数组,这会付出一定的开销。
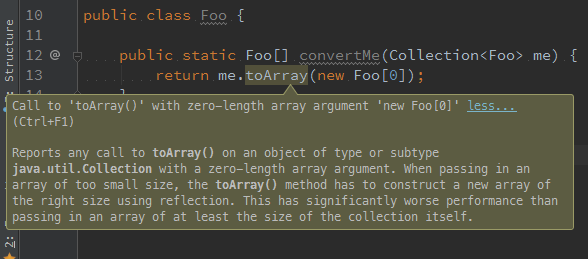
PMD 的 OptimizableToArrayCall 规则告诉我们同样的事情,但似乎还暗示了新分配的“空”数组将被丢弃,我们应该通过传递预先确定好长度的数组来避免这种情况。

前辈们到底有多聪明?
性能运行
实验装置
在我们进行实验前,我们需要了解它的自由度。至少有三个方面需要考虑:
-
集合的大小。PMD 的规则表明,分配将被丢弃的数组是徒劳的。这意味着我们希望涵盖一些小的集合,以了解“无意义”的数组实例化的开销。 我们还希望看到复制元素的成本为主的大型集合的性能如何。当然,为了避免“最佳性能点”,我们还会增加大小介于两者之间的集合测试。
-
toArray() 参数的形状。当然,我们想测试
toArray调用的所有变体。其中特别令人感兴趣的是使用零长数组和预确定长度的数组的调用, 但非类型化的toArray作为参考也非常有趣。 -
集合中 toArray() 的实现。IDEA 的建议说明了存在可能会降低性能的反射数组实例化。我们需要调查实际使用的集合。 大多数集合的行为与
AbstractCollection相同: 分配Object[]或T[]数组——在后一种情况下使用了java.lang.reflect.Array::newInstance分配T[]数组——然后使用迭代器将元素逐一复制到目标数组中。public abstract class AbstractCollection { public <T> T[] toArray(T[] a) { int size = size(); T[] r = (a.length >= size) ? a : (T[])Array.newInstance(a.getClass().getComponentType(), size); Iterator<E> it = iterator(); for (int i = 0; i < r.length; i++) { ... r[i] = (T)it.next(); } return ... r; } }某些集合(特别是
ArrayList)只需将它背后存储用的数组元素复制到目标数组中:public class ArrayList { public <T> T[] toArray(T[] a) { if (a.length < size) { // Arrays.copyOf would do the Array.newInstance return (T[]) Arrays.copyOf(elementData, size, a.getClass()); } System.arraycopy(elementData, 0, a, 0, size); if (a.length > size) { a[size] = null; } return a; } }ArrayList是最常用的集合类之一,因此我们希望了同时了解常用的ArrayList, 以及通用的基于AbstractCollection的集合(像HashSet)的性能。
基准
通过以上观察,我们可以构建出以下 JMH 基准:
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(value = 3, jvmArgsAppend = {"-XX:+UseParallelGC", "-Xms1g", "-Xmx1g"})
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
public class ToArrayBench {
@Param({"0", "1", "10", "100", "1000"})
int size;
@Param({"arraylist", "hashset"})
String type;
Collection<Foo> coll;
@Setup
public void setup() {
if (type.equals("arraylist")) {
coll = new ArrayList<Foo>();
} else if (type.equals("hashset")) {
coll = new HashSet<Foo>();
} else {
throw new IllegalStateException();
}
for (int i = 0; i < size; i++) {
coll.add(new Foo(i));
}
}
@Benchmark
public Object[] simple() {
return coll.toArray();
}
@Benchmark
public Foo[] zero() {
return coll.toArray(new Foo[0]);
}
@Benchmark
public Foo[] sized() {
return coll.toArray(new Foo[coll.size()]);
}
public static class Foo {
private int i;
public Foo(int i) {
this.i = i;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Foo foo = (Foo) o;
return i == foo.i;
}
@Override
public int hashCode() {
return i;
}
}
}
由于此基准是 GC 密集型的,因此固定 GC 算法和堆大小很重要,这样可以避免启发式算法带来的意外的行为改变。
性能数据
在相当大的 i7-4790K、4.0 GHz、Linux x86_64、JDK 9b99 EA 上运行,将产生(平均执行时间,越低越好):
Benchmark (size) (type) Mode Cnt Score Error Units
# ---------------------------------------------------------------------------
ToArrayBench.simple 0 arraylist avgt 30 19.445 ± 0.152 ns/op
ToArrayBench.sized 0 arraylist avgt 30 19.009 ± 0.252 ns/op
ToArrayBench.zero 0 arraylist avgt 30 4.590 ± 0.023 ns/op
ToArrayBench.simple 1 arraylist avgt 30 7.906 ± 0.024 ns/op
ToArrayBench.sized 1 arraylist avgt 30 18.972 ± 0.357 ns/op
ToArrayBench.zero 1 arraylist avgt 30 10.472 ± 0.038 ns/op
ToArrayBench.simple 10 arraylist avgt 30 8.499 ± 0.049 ns/op
ToArrayBench.sized 10 arraylist avgt 30 24.637 ± 0.128 ns/op
ToArrayBench.zero 10 arraylist avgt 30 15.845 ± 0.075 ns/op
ToArrayBench.simple 100 arraylist avgt 30 40.874 ± 0.352 ns/op
ToArrayBench.sized 100 arraylist avgt 30 93.170 ± 0.379 ns/op
ToArrayBench.zero 100 arraylist avgt 30 80.966 ± 0.347 ns/op
ToArrayBench.simple 1000 arraylist avgt 30 400.130 ± 2.261 ns/op
ToArrayBench.sized 1000 arraylist avgt 30 908.007 ± 5.869 ns/op
ToArrayBench.zero 1000 arraylist avgt 30 673.682 ± 3.586 ns/op
# ---------------------------------------------------------------------------
ToArrayBench.simple 0 hashset avgt 30 21.270 ± 0.424 ns/op
ToArrayBench.sized 0 hashset avgt 30 20.815 ± 0.400 ns/op
ToArrayBench.zero 0 hashset avgt 30 4.354 ± 0.014 ns/op
ToArrayBench.simple 1 hashset avgt 30 22.969 ± 0.221 ns/op
ToArrayBench.sized 1 hashset avgt 30 23.752 ± 0.503 ns/op
ToArrayBench.zero 1 hashset avgt 30 23.732 ± 0.076 ns/op
ToArrayBench.simple 10 hashset avgt 30 39.630 ± 0.613 ns/op
ToArrayBench.sized 10 hashset avgt 30 43.808 ± 0.629 ns/op
ToArrayBench.zero 10 hashset avgt 30 44.192 ± 0.823 ns/op
ToArrayBench.simple 100 hashset avgt 30 298.032 ± 3.925 ns/op
ToArrayBench.sized 100 hashset avgt 30 316.250 ± 9.614 ns/op
ToArrayBench.zero 100 hashset avgt 30 284.431 ± 6.201 ns/op
ToArrayBench.simple 1000 hashset avgt 30 4227.564 ± 84.983 ns/op
ToArrayBench.sized 1000 hashset avgt 30 4539.614 ± 135.379 ns/op
ToArrayBench.zero 1000 hashset avgt 30 4428.601 ± 205.191 ns/op
# ---------------------------------------------------------------------------
好吧,看起来 simple 转换胜过其他的一切,并且与直觉相反,zero 转换胜过了 sized 转换。
这这一点上,大多数人犯了一个重大错误:他们采用了这些数字,就像它们是真的一样。但这些数字只是数据,除非我们从中提炼出要点,否则它们没有任何意义。要做到这一点,我们需要了解为什么数字是这样的。
仔细查看数据,我们希望得到两个主要问题的答案:
- 为什么
simple似乎比zero和sized更快? - 为什么
zero似乎比sized更快?
回答这些问题是理解正在发生的事情的途径。
任何优秀的性能工程师,在开始调查前尝试猜测答案以找出实际答案是一种训练直觉的联系。花几分钟时间对这些问题做出合理的假设性回答。你需要做什么实验来证实这些假设?什么样的实验可以证伪它们?
不是分配压力
我想抛出一个简单的假设:分配压力。人们可能会猜测,不同的分配压力可以解释性能的差异。事实上许多 GC 密集型负载也是与 GC 绑定的,这意味着基准性能与 GC 性能紧密相连。
通常来说,把很多基准转换为与 GC 绑定的基准很容易。在我们的例子中,我们使用单个线程允许基准代码,这使得 GC 线程可以自由地在不同的核心上运行, 并使用多个 GC 线程收集单个基准线程的垃圾。添加更多基准线程将使他们:a) 与 GC 线程争夺 CPU 时间,从而隐式地计算 GC 时间; b) 产生更多垃圾,从而使每个应用程序线程的有效 GC 线程数下降,从而增加内存管理成本。
这就是为什么您通常希望同时在单线程和多线程(饱和)模式下运行基准测试的原因之一。在饱和模式下运行能够捕获系统正在执行的任何“隐秘”的卸载活动。
但是在我们的例子中,我们可以走捷径估测分配压力。为此,JMH 有一个 -prof gc 分析器,它监听 GC 事件,将它们相加,
并将分配/流失率标准化为 benchmark ops 的数量,为您提供每个 @Benchmark 调用的分配压力。
分配压力(该表仅展示“gc.alloc.rate.norm”指标)
Benchmark (size) (type) Mode Cnt Score Error Units
# ------------------------------------------------------------------------
ToArrayBench.simple 0 arraylist avgt 30 16.000 ± 0.001 B/op
ToArrayBench.sized 0 arraylist avgt 30 16.000 ± 0.001 B/op
ToArrayBench.zero 0 arraylist avgt 30 16.000 ± 0.001 B/op
ToArrayBench.simple 1 arraylist avgt 30 24.000 ± 0.001 B/op
ToArrayBench.sized 1 arraylist avgt 30 24.000 ± 0.001 B/op
ToArrayBench.zero 1 arraylist avgt 30 40.000 ± 0.001 B/op
ToArrayBench.simple 10 arraylist avgt 30 56.000 ± 0.001 B/op
ToArrayBench.sized 10 arraylist avgt 30 56.000 ± 0.001 B/op
ToArrayBench.zero 10 arraylist avgt 30 72.000 ± 0.001 B/op
ToArrayBench.simple 100 arraylist avgt 30 416.000 ± 0.001 B/op
ToArrayBench.sized 100 arraylist avgt 30 416.000 ± 0.001 B/op
ToArrayBench.zero 100 arraylist avgt 30 432.000 ± 0.001 B/op
ToArrayBench.simple 1000 arraylist avgt 30 4016.001 ± 0.001 B/op
ToArrayBench.sized 1000 arraylist avgt 30 4016.001 ± 0.002 B/op
ToArrayBench.zero 1000 arraylist avgt 30 4032.001 ± 0.001 B/op
# ------------------------------------------------------------------------
ToArrayBench.simple 0 hashset avgt 30 16.000 ± 0.001 B/op
ToArrayBench.sized 0 hashset avgt 30 16.000 ± 0.001 B/op
ToArrayBench.zero 0 hashset avgt 30 16.000 ± 0.001 B/op
ToArrayBench.simple 1 hashset avgt 30 24.000 ± 0.001 B/op
ToArrayBench.sized 1 hashset avgt 30 24.000 ± 0.001 B/op
ToArrayBench.zero 1 hashset avgt 30 24.000 ± 0.001 B/op
ToArrayBench.simple 10 hashset avgt 30 56.000 ± 0.001 B/op
ToArrayBench.sized 10 hashset avgt 30 56.000 ± 0.001 B/op
ToArrayBench.zero 10 hashset avgt 30 56.000 ± 0.001 B/op
ToArrayBench.simple 100 hashset avgt 30 416.000 ± 0.001 B/op
ToArrayBench.sized 100 hashset avgt 30 416.001 ± 0.001 B/op
ToArrayBench.zero 100 hashset avgt 30 416.001 ± 0.001 B/op
ToArrayBench.simple 1000 hashset avgt 30 4056.006 ± 0.009 B/op
ToArrayBench.sized 1000 hashset avgt 30 4056.007 ± 0.010 B/op
ToArrayBench.zero 1000 hashset avgt 30 4056.006 ± 0.009 B/op
# ------------------------------------------------------------------------
数据确实表明,在相同大小下分配压力基本相同。在某些情况下,zero 测试会多分配 16 字节——这是“冗余”数组分配的成本。
(读者练习:为什么 zero 在 HashSet 的情况下相同?)。但是,我们上面的吞吐量基准表明 zero 的情况更快,
而不是像分配压力假设所预测的那样更慢。因此,分配压力不能解释我们所看到的现象。
性能分析
在我们的领域,我们可以跳过假设的建立,直接使用强大的工具戳破这些东西。如果我们做一会事后诸葛亮,直接得出结论,这一部分可能更短。 但是这篇文章的要点之一是展示分析这些基准的方法。
认识 VisualVM(和其他仅限于 Java 的分析器)
最显然的方法是将 Java 分析器附加到基准 JVM 上,然后查看那里发生了什么。在不失通用性的情况下,让我们使用 JDK 本身附带的 VisualVM 分析器, 它可以在大多数安装中直接使用。
使用它非常容易:启动应用程序,启动 VisualVM(如果 JDK 在您的 PATH 中,直接执行 jvisualvm 就可以了),
从列表中选择一个目标 VM,从下拉列表或选项卡中选择 “Sample”,点击 “CPU Sampling”,然后享受结果。
让我们做一个测试,看看它显示了什么:
呃……信息量很大。
大多数 Java 分析器是有固有偏差的,因为它们要么插入代码,所以会导致真实结果偏差,要么在代码中的指定位置(例如安全点)采样,
这也会扭曲结果。在我们上面的例子中,虽然大部分工作是在 simple() 方法中完成的,但是分析器错误的将工作归因于保存基准循环的 …_jmhStub 方法。
但这不是这里的核心问题。对我们来说,最大的问题是缺少任何可以帮我们回答性能问题的低级细节。您能在上面的分析截图中看到任何可以验证我们的例子中任何合理假设的东西吗? 不能,因为数据太粗糙了。请注意,对于更大的工作负载来说这不是一个问题,因为性能现象展现在更大、更分散的调用树中。在这些工作负载中,偏差的影响被平摊了。
认识 JMH -prof perfasm
需要探索微基准的底层细节,这就是为什么好的微基准测试工具提供了一种清晰的方式剖解、分析和内省小的工作负载。 对于 JMH,我们有一个内置的 “perfasm” 分析器,它从 VM 中转储 PrintAssembly 的输出, 用 perf_events 计数器对其进行注释,并打印出最热点的部分。 perf_events 使用硬件计数器提供非侵入式采样分析,这是我们想要的细粒度性能工程。
以下是其中一项测试的示例输出:
$ java -jar target/benchmarks.jar zero -f 1 -p size=1000 -p type=arraylist -prof perfasm
....[Hottest Region 1].......................................................................
[0x7fc4c180916e:0x7fc4c180920c] in StubRoutines::checkcast_arraycopy
StubRoutines::checkcast_arraycopy [0x00007fc4c18091a0, 0x00007fc4c180926b]
0.04% 0x00007fc4c18091a0: push %rbp
0.06% 0.01% 0x00007fc4c18091a1: mov %rsp,%rbp
0.01% 0x00007fc4c18091a4: sub $0x10,%rsp
0.02% 0.01% 0x00007fc4c18091a8: mov %r13,(%rsp)
0.14% 0.02% 0x00007fc4c18091ac: mov %r14,0x8(%rsp)
0.07% 0.02% 0x00007fc4c18091b1: lea (%rdi,%rdx,4),%rdi
0.01% 0x00007fc4c18091b5: lea (%rsi,%rdx,4),%r13
0x00007fc4c18091b9: mov %rdx,%r14
0.02% 0x00007fc4c18091bc: neg %rdx
0.01% 0.01% ╭ 0x00007fc4c18091bf: jne 0x00007fc4c18091de
│ 0x00007fc4c18091c5: xor %rax,%rax
│ 0x00007fc4c18091c8: jmpq 0x00007fc4c1809260
│ 0x00007fc4c18091cd: data16 xchg %ax,%ax
19.30% 19.73% │↗↗↗ 0x00007fc4c18091d0: mov %eax,0x0(%r13,%rdx,4)
5.96% 6.89% ││││ 0x00007fc4c18091d5: inc %rdx
││││ 0x00007fc4c18091d8: je 0x00007fc4c1809233
3.84% 4.92% ↘│││ 0x00007fc4c18091de: mov (%rdi,%rdx,4),%eax
5.83% 6.56% │││ 0x00007fc4c18091e1: test %rax,%rax
╰││ 0x00007fc4c18091e4: je 0x00007fc4c18091d0
14.88% 20.52% ││ 0x00007fc4c18091e6: mov 0x8(%rax),%r11d
15.11% 19.60% ││ 0x00007fc4c18091ea: shl $0x3,%r11
10.65% 11.80% ││ 0x00007fc4c18091ee: cmp %r8,%r11
0.01% ╰│ 0x00007fc4c18091f1: je 0x00007fc4c18091d0
│ 0x00007fc4c18091f3: cmp (%r11,%rcx,1),%r8
╰ 0x00007fc4c18091f7: je 0x00007fc4c18091d0
0x00007fc4c18091f9: cmp $0x18,%ecx
0x00007fc4c18091fc: jne 0x00007fc4c1809223
0x00007fc4c1809202: push %rax
0x00007fc4c1809203: mov %r8,%rax
0x00007fc4c1809206: push %rcx
0x00007fc4c1809207: push %rdi
0x00007fc4c1809208: mov 0x20(%r11),%rdi
0x00007fc4c180920c: mov (%rdi),%ecx
.............................................................................................
75.96% 90.09% <total for region 1>
它显示出最热点的部分在神秘的 StubRoutines::checkcast_arraycopy 代码块中的某个地方。
稍后我们将深入讨论,但主要的结论是我们的性能现象存在于生成的代码中,甚至可能不是来自从 Java 代码生成的代码中。
虽然本文中进一步得出的关键点可以从 perfasm 中得到,但我想专注于另一个更传统的选项,并且可以扩展到更大的工作负载上。
认识 Solaris Studio 性能分析器
想象一下,我们想要一个分析器,结合了无偏差的 Java/本机分析,和可选的硬件计数器分析?我们有一个应用可以做到它! 令人困惑的是,他被称为 Solaris Studio 性能分析器,尽管它也可以在 Linux 上运行。
分析器有几个适用的工作流,下面时我们在试验中主要使用的工作流。分析器有两个不同的部分:收集性能数据的 collect 工具和可用于处理结果的 GUI analyzer。 虽然您可以从 GUI 中启动/连接到正在运行的进程,但拥有 CLI collect 工具非常方便,因为您可以定义几个可重用的 shell 别名:
$ tail ~/.bashrc
# Collect Java+native, clock profiling
alias 'perfanal'="collect -o test.1.er -S on -j on -A on "
# Collect native only (useful when loading *lots* of classes
# -- avoids profiler's JVMTI hooks overheads), clock profiling
alias 'perfanal-native'="collect -o test.1.er -S on -j off -A on "
# Collect Java+native, hardware counter profiling
alias 'perfanal-hwc'="collect -o test.1.er -S on -j on -A on -h cycles,on,insts,on "
# Collect native only, hardware counting profiling
alias 'perfanal-hwc-native'="collect -o test.1.er -S on -j off -A on -h cycles,on,insts,on "
这些别名允许您像这样快速地将分析器附加到 JMH:
$ perfanal-hwc java -jar benchmarks.jar -f 1 -p size=1000 -p type=arraylist
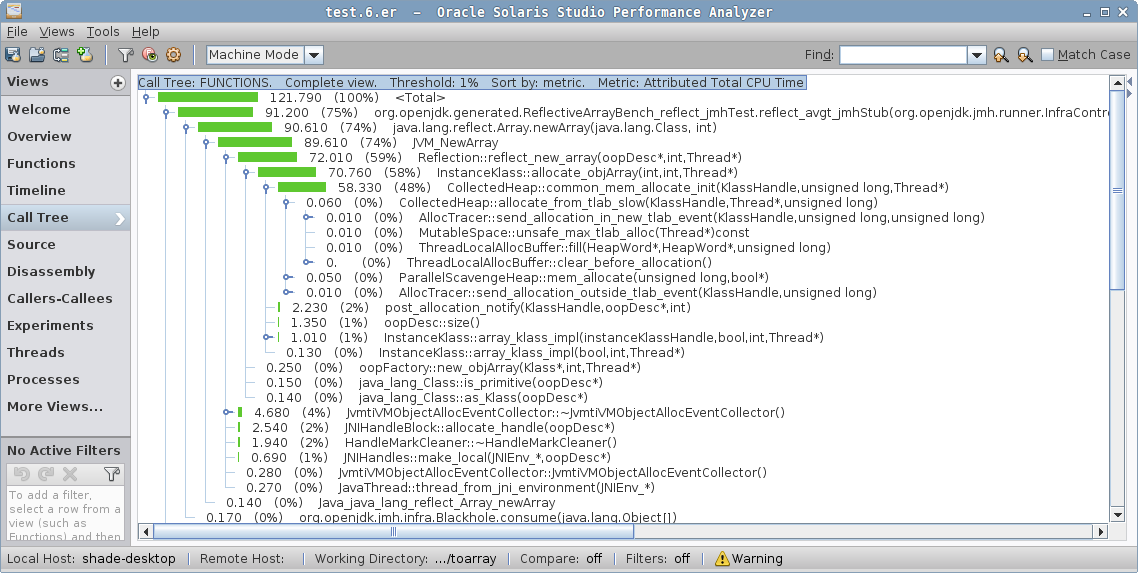
这将在当前目录中创建 test.${n}.er 结果文件,然后您可以用分析器 GUI 打开。GUI 足够丰富,可以直观地理解,下面是我们在其中看到的结果。
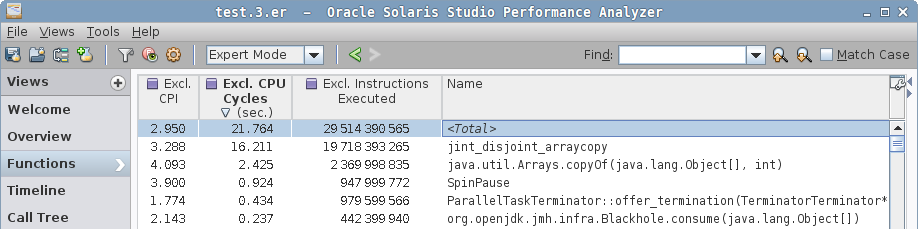
在一个简单的例子中,我们看到最热点的函数是 jint_disjoint_arraycopy,它似乎是为不相交的数组实现 “int” arraycopy 的函数。
请注意分析器如何解析 Java 代码(
org.openjdk…)、VM 本机代码(ParallelTaskTerminator::…和SpinPause)与生成的 VM 存根(例如jint_disjoint_arraycopy)的。 在复杂场景中,调用树会同时显示 Java 和本机帧,这在调试 JNI/JNA 例子时非常有用,包括对 VM 本身的调用。
“Call Tree” 会告诉你这个
jint_disjoint_arraycopy是一个叶函数。关于这个函数是什么,并没有其他标识,但您可以在 HotSpot 源代码库中搜索, 然后你会发现 stubRoutines.hpp, 它会说 “StubRoutines provides entry points to assembly routines used by compiled code and the run-time system. Platform-specific entry points are defined in the platform-specific inner class.” 编译器和运行时都用它来优化某些操作,特别是 arraycopy。
![图五:ArrayList (size = 1000), toArray(new T[list.size()])](https://shipilev.net/blog/2016/arrays-wisdom-ancients/analyzer-functions-sized.png)
在 sized 例子中,我们看到 arraycopy 的另一个函数 checkcast_arraycopy,以及 sized() 方法的 Java 代码。
![图六:ArrayList (size = 1000), toArray(new T[0])](https://shipilev.net/blog/2016/arrays-wisdom-ancients/analyzer-functions-zero.png)
在 zero 例子中,我们看到另一个竞争者 checkcast_arraycopy_uninit,它看起来像是 checkcast_arraycopy 的修改版,但是“未初始化”?
请注意,Java 方法已经从热点中消失。
好,函数的名称已经很有启发性了,但在我们使用分析器的另一个出色功能前,这只是一个有根据的猜测。如果我们从列表(或者 “Call Tree”)中选择函数, 并切换到 “Disassembly” 视图,我们将看到……等等……反汇编!
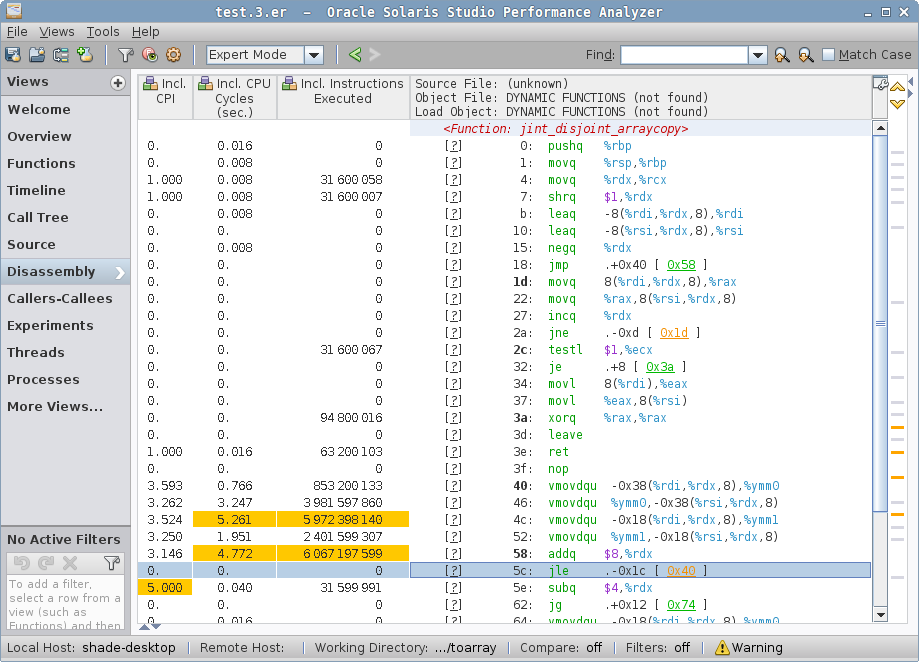
jint_disjoint_arraycopy 实际上就是复制用的存根,它使用 AVX 进行向量化复制!难怪它这么快:它可以大步的复制背后的存储数据。
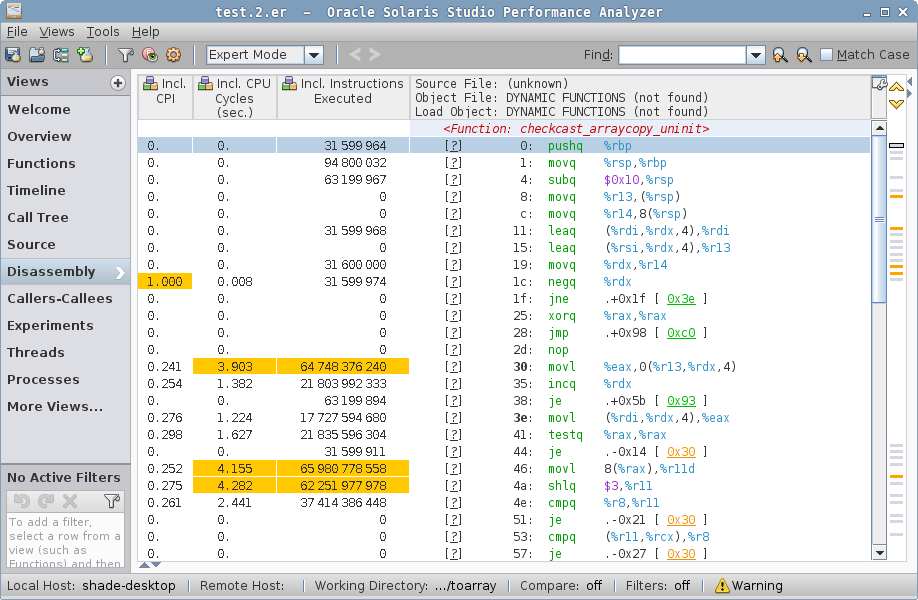
zero 例子的反汇编显示了非向量化的 checkcast_arraycopy_uninit。它有什么作用?相对地址 30-51 处的循环确实在复制,但它似乎根本没有被向量化。
唉,辨认它的功能需要一些 VM 内部知识。通常,您可以将 Java 源代码附加到汇编,但 VM 存根没有与之关联的 Java 源代码。
您还可以追踪生成存根的 VM 源代码。在这里,我们将耐心地关注于这段代码。
循环使用 movl(%rdi,%rdx,4),%eax 进行读取,movl %eax, 0(%r13,%rdx,4) 进行写入,然后增加 %rdx——由此可知 %rdx 是循环计数器。
在将当前成员读取到 %eax 后,我们对它进行空检查,从偏移量 0x8 处加载某个成员,对其位移,并与其他成员进行对比。
这就是加载一个 class word,对它解包,并对其进行类型检查。
您可以使用 JOL 查看 Java 对象的运行时表示。注意,请参见 JOLSample_11_ClassWord example。
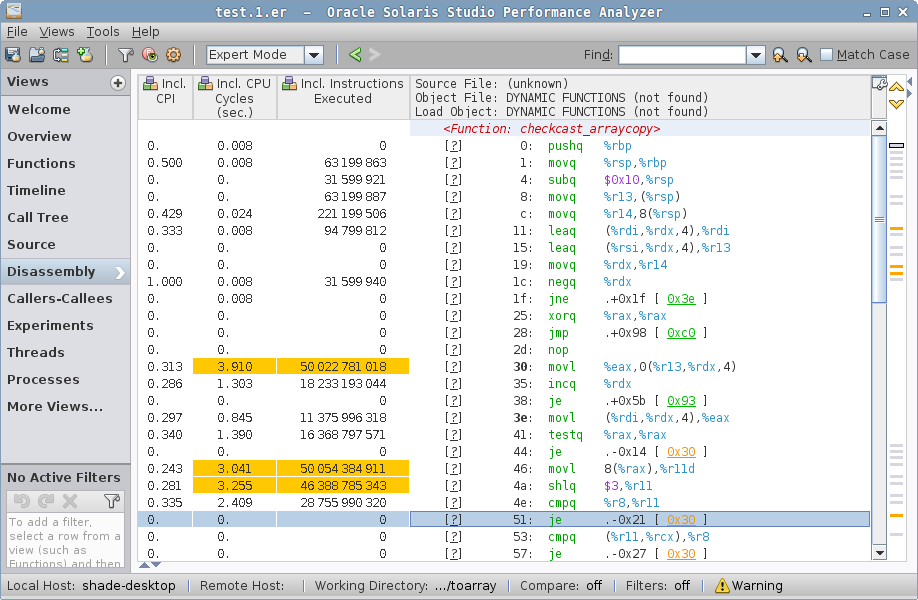
sized 有两个热点,一个在 checkcast_arraycopy 中,其中的热循环实际上和上面的 zero 例子中的相同,但让我们来到第二个热点:
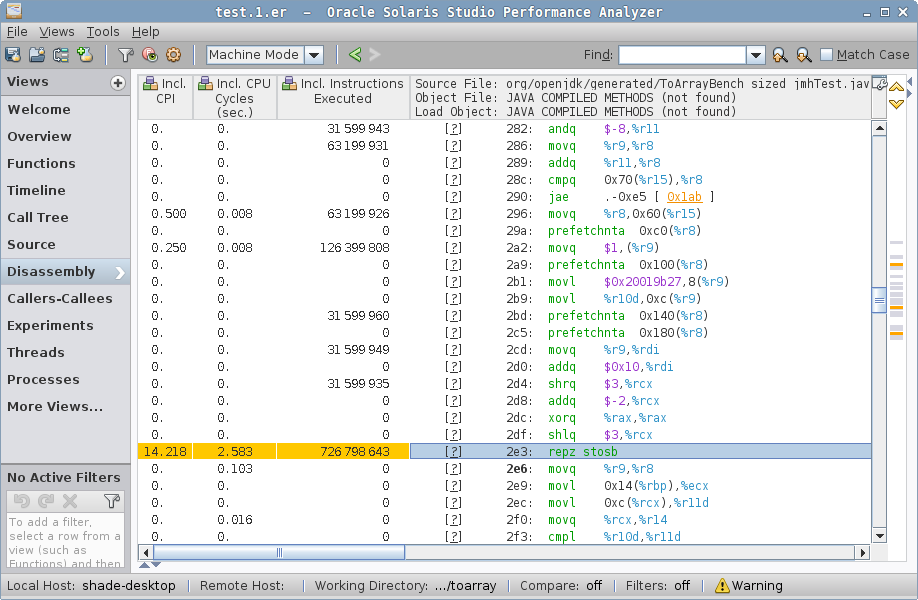
……这将大部分周期归因于 repz stosb 指令。在您查看生成的代码之前,这很神秘。
HotSpot 生成的代码中 prefetchnta 指令通常属于 “分配预载”(请参阅命令行文档:-XX:Allocate…),
这与对象分配有关。事实上,我们在 %r9 中有“新”对象地址,我们放入 mark word、class word,然后用 repz stosb 将存储归零——这是变相的“memset to zero”。
分配本身是一个数组分配,我们看到的是数组归零。您可以在“Why Nothing Matters: The Impact of Zeroing”中更详细地了解这一点。
准备工作
有了这个,我们有了初步答案:
simple例子中的向量化 arraycopy 比sized和zero例子中需要类型检查的 arraycopy 快得多。- 神奇地避免数组归零可以让
zero比sized更快。“反射”数组创建似乎根本不会影响到zero例子。
对 HashSet 重做相同的操作留给读者作为练习:它将带来大致相同的初步答案。
后续工作
在很多情况下,跟进您刚刚从目标工作负载中得到的结果,从而了解结论的普遍性和自己是否很好地理解了它们是很有教育意义的。 Beware, this is the Rabbit Hole of Performance Engineering — you cannot finish the dive, you can only stop it.
反射创建数组
首先,让我们来解构“反射创建数组速度慢”的观点。我们知道很多集合使用 Array.newInstance(Class<?>,int) 实例化给定类型的数组——我们为什么不试试呢?
让我们看一下,考虑到相同的基准测试思想,让我们去除 newInstance 调用以外的内容:
@Warmup(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(value = 3, jvmArgsAppend = {"-XX:+UseParallelGC", "-Xms1g", "-Xmx1g"})
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
public class ReflectiveArrayBench {
@Param({"0", "1", "10", "100", "1000"})
int size;
@Benchmark
public Foo[] lang() {
return new Foo[size];
}
@Benchmark
public Foo[] reflect() {
return (Foo[]) Array.newInstance(Foo.class, size);
}
}
现在如果您查看性能数据,会发现通过“语言”表达式实例化数组的性能与反射调用的性能是相同的:
Benchmark (size) Mode Cnt Score Error Units
# default
ReflectiveArrayBench.lang 0 avgt 5 17.065 ± 0.224 ns/op
ReflectiveArrayBench.lang 1 avgt 5 12.372 ± 0.112 ns/op
ReflectiveArrayBench.lang 10 avgt 5 14.910 ± 0.850 ns/op
ReflectiveArrayBench.lang 100 avgt 5 42.942 ± 3.666 ns/op
ReflectiveArrayBench.lang 1000 avgt 5 267.889 ± 15.719 ns/op
# default
ReflectiveArrayBench.reflect 0 avgt 5 17.010 ± 0.299 ns/op
ReflectiveArrayBench.reflect 1 avgt 5 12.542 ± 0.322 ns/op
ReflectiveArrayBench.reflect 10 avgt 5 12.835 ± 0.587 ns/op
ReflectiveArrayBench.reflect 100 avgt 5 42.691 ± 2.204 ns/op
ReflectiveArrayBench.reflect 1000 avgt 5 264.408 ± 22.079 ns/op
这是为什么?我们昂贵的反射调用在哪里?为了缩短追踪的时间,您通常可以通过执行以下步骤来平分这种“古怪”。 首先,请 Google 或记住,在很长一段时间内反射调用会“膨胀”(从每次调用成本较高但避免了一次性设置的 JNI 调用,过渡到到达阈值后生成的更快的无 JNI 代码)。 关闭反射膨胀后:
Benchmark (size) Mode Cnt Score Error Units
# -Dsun.reflect.inflationThreshold=2147483647
ReflectiveArrayBench.reflect 0 avgt 10 17.253 ± 0.470 ns/op
ReflectiveArrayBench.reflect 1 avgt 10 12.418 ± 0.101 ns/op
ReflectiveArrayBench.reflect 10 avgt 10 12.554 ± 0.109 ns/op
ReflectiveArrayBench.reflect 100 avgt 10 39.969 ± 0.367 ns/op
ReflectiveArrayBench.reflect 1000 avgt 10 252.281 ± 2.630 ns/op
嗯,不是这样的。让我们深入了解源代码:
jdk/src/java.base/share/classes/java/lang/reflect/Array.java
class Array {
public static Object newInstance(Class<?> componentType, int length)
throws NegativeArraySizeException {
return newArray(componentType, length);
}
@HotSpotIntrinsicCandidate // <--- Ohh, what's this?
private static native Object newArray(Class<?> componentType, int length)
throws NegativeArraySizeException;
}
jdk/src/java.base/share/classes/jdk/internal/HotSpotIntrinsicCandidate.java
/**
* The {@code @HotSpotIntrinsicCandidate} annotation is specific to the
* HotSpot Virtual Machine. It indicates that an annotated method
* may be (but is not guaranteed to be) intrinsified by the HotSpot VM. A method
* is intrinsified if the HotSpot VM replaces the annotated method with hand-written
* assembly and/or hand-written compiler IR -- a compiler intrinsic -- to improve
* performance. The {@code @HotSpotIntrinsicCandidate} annotation is internal to the
* Java libraries and is therefore not supposed to have any relevance for application
* code.
*/
public @interface HotSpotIntrinsicCandidate { ... }
因此,VM 明白 Array.newArray 方法。有趣的是,让我们看看它的名字:
hotspot/src/share/vm/classfile/vmSymbols.hpp
do_intrinsic(_newArray, java_lang_reflect_Array, newArray_name, newArray_signature, F_SN) \
do_name( newArray_name, "newArray") \
do_signature(newArray_signature, "(Ljava/lang/Class;I)Ljava/lang/Object;") \
Intrinsic,嗯?让我试试禁用你:
# -XX:+UnlockDiagnosticVMOptions -XX:DisableIntrinsic=_newArray
ReflectiveArrayBench.reflect 0 avgt 5 67.594 ± 4.795 ns/op
ReflectiveArrayBench.reflect 1 avgt 5 69.935 ± 7.766 ns/op
ReflectiveArrayBench.reflect 10 avgt 5 73.588 ± 0.329 ns/op
ReflectiveArrayBench.reflect 100 avgt 5 86.598 ± 1.735 ns/op
ReflectiveArrayBench.reflect 1000 avgt 5 409.786 ± 9.148 ns/op
啊哈,这里!这由 JVM 特殊处理,并生成相同的代码。但是,永远不要您在互联网上看到的任何“fancy”的选项都会做出不您认为它会做的事情。 让我们看看性能分析器中的概述:
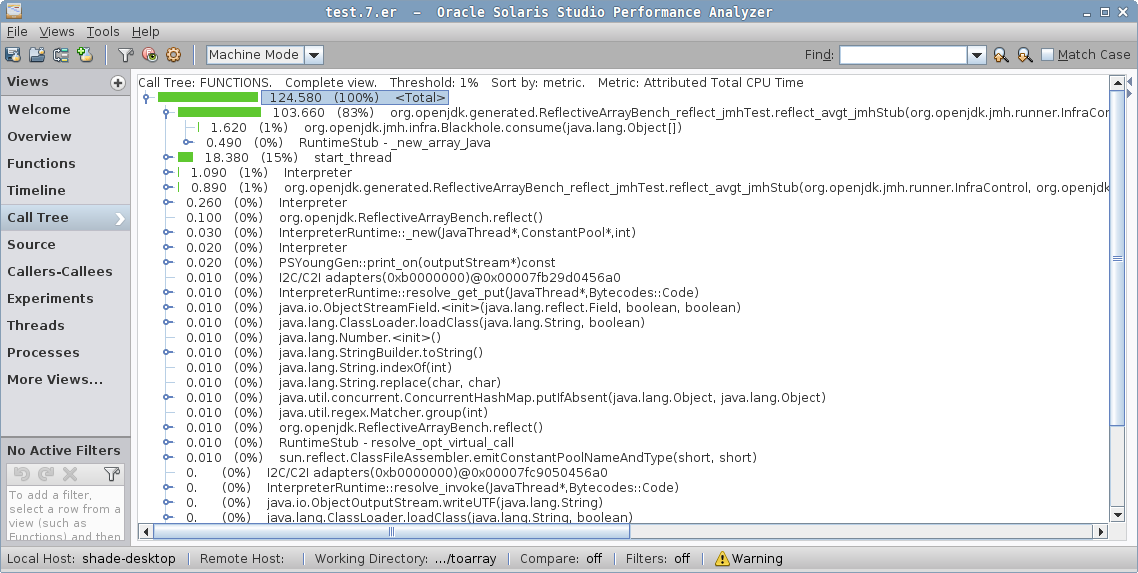
看到区别了吗?当 intrinsic 被禁用时,我们有 Array.newArray 的 Java 方法,然后调用 JVM_NewArray 本机方法实现,
然后调用 VM 的 Reflection::…,然后从那里向 GC 请求分配数组。这一定就是人们看到的昂贵的“Array.newArray 调用”。
但这不再是试试。JIRA 历史指出 JDK-6525802 中修复了它。稍后我们将探索历史性能数据。
空数组实例化
现在让我们把注意力转向数组实例化成本上。在我们跳到归零消除前,了解分配本身的工作原理很重要。 事后看来,我们希望同时测量常量大小的数组和无法静态得知数组大小的非常量大小数组。编译器可以利用这些知识做到什么吗?
让我们看看,并这样构建 JMH 基准测试(我是用伪宏语言描述它,让它更短):
@Warmup(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(value = 3, jvmArgsAppend = {"-XX:+UseParallelGC", "-Xms1g", "-Xmx1g"})
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
public class EmptyArrayBench {
#for L in 0..512
int v$L = $L;
@Benchmark
public Foo[] field_$L() {
return new Foo[v$L];
}
@Benchmark
public Foo[] const_$L() {
return new Foo[$L];
}
#done
}
运行该基准测试将产生像这样的结果:
Benchmark Mode Cnt Score Error Units
# -----------------------------------------------------------
EmptyArrayBench.const_000 avgt 15 2.847 ± 0.016 ns/op
EmptyArrayBench.const_001 avgt 15 3.090 ± 0.020 ns/op
EmptyArrayBench.const_002 avgt 15 3.083 ± 0.022 ns/op
EmptyArrayBench.const_004 avgt 15 3.336 ± 0.029 ns/op
EmptyArrayBench.const_008 avgt 15 4.618 ± 0.047 ns/op
EmptyArrayBench.const_016 avgt 15 7.568 ± 0.061 ns/op
EmptyArrayBench.const_032 avgt 15 13.935 ± 0.098 ns/op
EmptyArrayBench.const_064 avgt 15 25.905 ± 0.183 ns/op
EmptyArrayBench.const_128 avgt 15 52.807 ± 0.252 ns/op
EmptyArrayBench.const_256 avgt 15 110.208 ± 1.006 ns/op
EmptyArrayBench.const_512 avgt 15 171.864 ± 0.777 ns/op
# -----------------------------------------------------------
EmptyArrayBench.field_000 avgt 15 16.998 ± 0.063 ns/op
EmptyArrayBench.field_001 avgt 15 12.400 ± 0.065 ns/op
EmptyArrayBench.field_002 avgt 15 12.651 ± 0.332 ns/op
EmptyArrayBench.field_004 avgt 15 12.434 ± 0.062 ns/op
EmptyArrayBench.field_008 avgt 15 12.504 ± 0.049 ns/op
EmptyArrayBench.field_016 avgt 15 12.588 ± 0.065 ns/op
EmptyArrayBench.field_032 avgt 15 14.423 ± 0.121 ns/op
EmptyArrayBench.field_064 avgt 15 26.145 ± 0.166 ns/op
EmptyArrayBench.field_128 avgt 15 53.092 ± 0.291 ns/op
EmptyArrayBench.field_256 avgt 15 110.275 ± 1.304 ns/op
EmptyArrayBench.field_512 avgt 15 174.326 ± 1.642 ns/op
# -----------------------------------------------------------
哎呀。看起来 field_* 测试在较小长度的情况下输掉了。为什么会这样?-prof perfasm 有一个提示:
Hottest allocation code in const_0008:
2.30% 1.07% 0x00007f32cd1f9f76: prefetchnta 0xc0(%r10)
3.34% 3.88% 0x00007f32cd1f9f7e: movq $0x1,(%rax)
3.66% 4.39% 0x00007f32cd1f9f85: prefetchnta 0x100(%r10)
1.63% 1.91% 0x00007f32cd1f9f8d: movl $0x20018fbd,0x8(%rax)
1.76% 2.31% 0x00007f32cd1f9f94: prefetchnta 0x140(%r10)
1.52% 2.14% 0x00007f32cd1f9f9c: movl $0x8,0xc(%rax)
2.77% 3.67% 0x00007f32cd1f9fa3: prefetchnta 0x180(%r10)
1.77% 1.80% 0x00007f32cd1f9fab: mov %r12,0x10(%rax)
4.40% 4.61% 0x00007f32cd1f9faf: mov %r12,0x18(%rax)
4.64% 3.97% 0x00007f32cd1f9fb3: mov %r12,0x20(%rax)
4.83% 4.49% 0x00007f32cd1f9fb7: mov %r12,0x28(%rax)
2.03% 2.71% 0x00007f32cd1f9fbb: mov %r8,0x18(%rsp)
1.35% 1.25% 0x00007f32cd1f9fc0: mov %rax,%rdx
Hottest allocation code in field_0008:
0.02% 0x00007f27551fb424: prefetchnta 0xc0(%r11)
5.53% 7.55% 0x00007f27551fb42c: movq $0x1,(%r9)
0.02% 0x00007f27551fb433: prefetchnta 0x100(%r11)
0.05% 0.06% 0x00007f27551fb43b: movl $0x20018fbd,0x8(%r9)
0.01% 0x00007f27551fb443: mov %edx,0xc(%r9)
2.03% 1.78% 0x00007f27551fb447: prefetchnta 0x140(%r11)
0.04% 0.07% 0x00007f27551fb44f: mov %r9,%rdi
0.02% 0.02% 0x00007f27551fb452: add $0x10,%rdi
0.02% 0.01% 0x00007f27551fb456: prefetchnta 0x180(%r11)
1.96% 1.05% 0x00007f27551fb45e: shr $0x3,%rcx
0.02% 0.02% 0x00007f27551fb462: add $0xfffffffffffffffe,%rcx
0.01% 0.03% 0x00007f27551fb466: xor %rax,%rax
0.01% 0x00007f27551fb469: shl $0x3,%rcx
1.96% 0.06% 0x00007f27551fb46d: rep rex.W stos %al,%es:(%rdi) ; <--- huh...
39.44% 78.39% 0x00007f27551fb470: mov %r8,0x18(%rsp)
8.01% 0.18% 0x00007f27551fb475: mov %r9,%rdx
进一步挖掘,您会注意到,即使是 const_* 的情况下,在某个阈值后也会切换回 rep stos(这与其他 memset 的实现差不多),
而在较小的大小上避免 rep stos 的设置成本。但是在 field_* 的情况下,不知道静态的长度,所以总是做 rep stos,
在较小的长度上也会付出惩罚成本。
这在某种程度上是可以解决的,请参见 JDK-8146801。
但是,常量大小至少会更好。您知道这是怎样适用于我们的 toArray 例子的吗? 在小集合上比较 new T[0] 和 new T[coll.size()]。
这就部分解答了为什么 zero 例子在较小大小上会获得“异常”的优势。
这是“编译器对代码的假设越多,优化效果越好”的另一个例子。常量法则! “Faster Atomic*FieldUpdaters for Everyone” 中描述了一个更有趣一些的案例。
未初始化的数组
现在进入故事的“归零”部分。Java 语言规范要求新实例化的数组和对象字段具有默认值(零),而不是内存中剩余的一些任意值。 因此运行时必须将分配的存储归零。但是如果我们在对象/数组对其他部分可见之前用一些初始值覆盖该存储, 那么我们就可以把初始化和归零合并,从而有效地消除归零。请注意,在遇到异常返回、finalizer 和其他 VM 内部结构时, “可见”可能很难定义,例如 JDK-8074566。
我们可以看到 zero 例子成功避免了归零,但 sized 例子没有。这是疏忽吗?为了探索这一点,我们可能想要评估不同的分配数组代码,
然后用 arraycopy 覆盖其内容。像这样:
@Warmup(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(value = 3, jvmArgsAppend = {"-XX:+UseParallelGC", "-Xms1g", "-Xmx1g"})
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
public class ArrayZeroingBench {
@Param({"1", "10", "100", "1000"})
int size;
Object[] src;
@Setup
public void setup() {
src = new Object[size];
for (int c = 0; c < size; c++) {
src[c] = new Foo();
}
}
@Benchmark
public Foo[] arraycopy_base() {
Object[] src = this.src;
Foo[] dst = new Foo[size];
System.arraycopy(src, 0, dst, 0, size - 1);
return dst;
}
@Benchmark
public Foo[] arraycopy_field() {
Object[] src = this.src;
Foo[] dst = new Foo[size];
System.arraycopy(src, 0, dst, 0, size);
return dst;
}
@Benchmark
public Foo[] arraycopy_srcLength() {
Object[] src = this.src;
Foo[] dst = new Foo[size];
System.arraycopy(src, 0, dst, 0, src.length);
return dst;
}
@Benchmark
public Foo[] arraycopy_dstLength() {
Object[] src = this.src;
Foo[] dst = new Foo[size];
System.arraycopy(src, 0, dst, 0, dst.length);
return dst;
}
@Benchmark
public Foo[] copyOf_field() {
return Arrays.copyOf(src, size, Foo[].class);
}
@Benchmark
public Foo[] copyOf_srcLength() {
return Arrays.copyOf(src, src.length, Foo[].class);
}
public static class Foo {}
}
运行该基准测试将得到一些有趣的结果:
Benchmark (size) Mode Cnt Score Error Units
AZB.arraycopy_base 1 avgt 15 14.509 ± 0.066 ns/op
AZB.arraycopy_base 10 avgt 15 23.676 ± 0.557 ns/op
AZB.arraycopy_base 100 avgt 15 92.557 ± 0.920 ns/op
AZB.arraycopy_base 1000 avgt 15 899.859 ± 7.303 ns/op
AZB.arraycopy_dstLength 1 avgt 15 17.929 ± 0.069 ns/op
AZB.arraycopy_dstLength 10 avgt 15 23.613 ± 0.368 ns/op
AZB.arraycopy_dstLength 100 avgt 15 92.553 ± 0.432 ns/op
AZB.arraycopy_dstLength 1000 avgt 15 902.176 ± 5.816 ns/op
AZB.arraycopy_field 1 avgt 15 18.063 ± 0.375 ns/op
AZB.arraycopy_field 10 avgt 15 23.443 ± 0.278 ns/op
AZB.arraycopy_field 100 avgt 15 93.207 ± 1.565 ns/op
AZB.arraycopy_field 1000 avgt 15 908.663 ± 18.383 ns/op
AZB.arraycopy_srcLength 1 avgt 15 8.658 ± 0.058 ns/op
AZB.arraycopy_srcLength 10 avgt 15 14.114 ± 0.084 ns/op
AZB.arraycopy_srcLength 100 avgt 15 79.778 ± 0.639 ns/op
AZB.arraycopy_srcLength 1000 avgt 15 681.040 ± 9.536 ns/op
AZB.copyOf_field 1 avgt 15 9.383 ± 0.053 ns/op
AZB.copyOf_field 10 avgt 15 14.729 ± 0.091 ns/op
AZB.copyOf_field 100 avgt 15 81.198 ± 0.477 ns/op
AZB.copyOf_field 1000 avgt 15 671.670 ± 6.723 ns/op
AZB.copyOf_srcLength 1 avgt 15 8.150 ± 0.409 ns/op
AZB.copyOf_srcLength 10 avgt 15 13.214 ± 0.112 ns/op
AZB.copyOf_srcLength 100 avgt 15 80.718 ± 1.583 ns/op
AZB.copyOf_srcLength 1000 avgt 15 671.716 ± 5.499 ns/op
当然,您需要研究研究这些生成的代码来验证关于这些结果的假设,事实上我们在 JDK-8146828 中也做过了。
VM 尝试尽可能的多消除归零,因为这会带来很大的好处——这就是为什么 zero 案例(类似于 copyOf_*)代码形状有优势的原因。
但是某些情况下,代码形状不会被识别为“紧密耦合”分配,并且不会消除归零,这应该被修复了,请参见 JDK-8146828。
缓存数组
很多人可能会问另一个后续问题:鉴于 zero 已经得到了很好的优化,我们是否可以进一步推进它,使用大小为零的静态常量数组来传递类型信息?
这样我们就可以完全避免不必要的分配了?让我们看看,并添加 zero_cached 测试:
@State(Scope.Benchmark)
public class ToArrayBench {
// Note this is *both* static *and* final
private static final Foo[] EMPTY_FOO = new Foo[0];
...
@Benchmark
public Foo[] zero() {
return coll.toArray(new Foo[0]);
}
@Benchmark
public Foo[] zero_cached() {
return coll.toArray(EMPTY_FOO);
}
}
请注意,这些案例略有不同:对于空集合,zero_cached 将返回相同的数组,而不是每次调用返回不同的数组。
如果用户使用数组标识进行某种操作,这可能会产生问题,而且这让在所有地方自动进行这种替换的希望化作泡影。
运行此基准将生成:
Benchmark (size) (type) Mode Cnt Score Error Units
# ----------------------------------------------------------------------------
ToArrayBench.zero 0 arraylist avgt 15 4.352 ± 0.034 ns/op
ToArrayBench.zero 1 arraylist avgt 15 10.574 ± 0.075 ns/op
ToArrayBench.zero 10 arraylist avgt 15 15.965 ± 0.166 ns/op
ToArrayBench.zero 100 arraylist avgt 15 81.729 ± 0.650 ns/op
ToArrayBench.zero 1000 arraylist avgt 15 685.616 ± 6.637 ns/op
ToArrayBench.zero_cached 0 arraylist avgt 15 4.031 ± 0.018 ns/op
ToArrayBench.zero_cached 1 arraylist avgt 15 10.237 ± 0.104 ns/op
ToArrayBench.zero_cached 10 arraylist avgt 15 15.401 ± 0.903 ns/op
ToArrayBench.zero_cached 100 arraylist avgt 15 82.643 ± 1.040 ns/op
ToArrayBench.zero_cached 1000 arraylist avgt 15 688.412 ± 18.273 ns/op
# ----------------------------------------------------------------------------
ToArrayBench.zero 0 hashset avgt 15 4.382 ± 0.028 ns/op
ToArrayBench.zero 1 hashset avgt 15 23.877 ± 0.139 ns/op
ToArrayBench.zero 10 hashset avgt 15 44.172 ± 0.353 ns/op
ToArrayBench.zero 100 hashset avgt 15 282.852 ± 1.372 ns/op
ToArrayBench.zero 1000 hashset avgt 15 4370.370 ± 64.018 ns/op
ToArrayBench.zero_cached 0 hashset avgt 15 3.525 ± 0.005 ns/op
ToArrayBench.zero_cached 1 hashset avgt 15 23.791 ± 0.162 ns/op
ToArrayBench.zero_cached 10 hashset avgt 15 44.128 ± 0.203 ns/op
ToArrayBench.zero_cached 100 hashset avgt 15 282.052 ± 1.469 ns/op
ToArrayBench.zero_cached 1000 hashset avgt 15 4329.551 ± 36.858 ns/op
# ----------------------------------------------------------------------------
正如预期中的样子,这只会在在集合大小很小的情况下观察到一定影响,这只是对 new Foo[0] 很小的改进。
这种改进似乎并不能证明在总体方案中缓存数组是合理的。作为一个小的微优化,它在一些要求严格的代码中可能有意义,但我不在乎。
历史视角
现在稍微回溯一下,看看原始基准测试在不同历史版本 JDK 上的表现如何。JMH 基准测试可以在从 JDK 6 开始的任何 JDK 上运行。 /me blows some dust from JDK releases archive.让我们讨论一下 JDK 6 生命周期中的几个有趣的点, 并看看最新的 JDK 8u66 与 JDK 9b99 的表现如何。
我们不需要所有的大小,只需要考虑一些合理的大小:
Benchmark (size) (type) Mode Cnt Score Error Units
# --------------------------------------------------------------------------
# 6u6 (2008-04-16)
ToArrayBench.simple 100 arraylist avgt 30 122.228 ± 1.413 ns/op
ToArrayBench.sized 100 arraylist avgt 30 139.403 ± 1.024 ns/op
ToArrayBench.zero 100 arraylist avgt 30 155.176 ± 3.673 ns/op
# 6u12 (2008-12-12)
ToArrayBench.simple 100 arraylist avgt 30 84.760 ± 1.283 ns/op
ToArrayBench.sized 100 arraylist avgt 30 142.400 ± 2.696 ns/op
ToArrayBench.zero 100 arraylist avgt 30 94.132 ± 0.636 ns/op
# 8u66 (2015-11-16)
ToArrayBench.simple 100 arraylist avgt 30 41.174 ± 0.953 ns/op
ToArrayBench.sized 100 arraylist avgt 30 93.159 ± 0.368 ns/op
ToArrayBench.zero 100 arraylist avgt 30 80.193 ± 0.362 ns/op
# 9b99 (2016-01-05)
ToArrayBench.simple 100 arraylist avgt 30 40.874 ± 0.352 ns/op
ToArrayBench.sized 100 arraylist avgt 30 93.170 ± 0.379 ns/op
ToArrayBench.zero 100 arraylist avgt 30 80.966 ± 0.347 ns/op
# --------------------------------------------------------------------------
# 6u12 (2008-12-12)
ToArrayBench.simple 100 hashset avgt 30 585.766 ± 5.946 ns/op
ToArrayBench.sized 100 hashset avgt 30 670.119 ± 0.959 ns/op
ToArrayBench.zero 100 hashset avgt 30 745.802 ± 5.309 ns/op
# 6u16 (2009-08-11)
ToArrayBench.simple 100 hashset avgt 30 561.724 ± 5.094 ns/op
ToArrayBench.sized 100 hashset avgt 30 634.155 ± 0.557 ns/op
ToArrayBench.zero 100 hashset avgt 30 634.300 ± 1.206 ns/op
# 6u21 (2010-07-07)
ToArrayBench.simple 100 hashset avgt 30 565.139 ± 3.763 ns/op
ToArrayBench.sized 100 hashset avgt 30 623.901 ± 4.027 ns/op
ToArrayBench.zero 100 hashset avgt 30 605.833 ± 2.909 ns/op
# 8u66 (2015-11-16)
ToArrayBench.simple 100 hashset avgt 30 297.281 ± 1.258 ns/op
ToArrayBench.sized 100 hashset avgt 30 387.633 ± 0.787 ns/op
ToArrayBench.zero 100 hashset avgt 30 307.410 ± 6.981 ns/op
# 9b99 (2016-01-05)
ToArrayBench.simple 100 hashset avgt 30 298.032 ± 3.925 ns/op
ToArrayBench.sized 100 hashset avgt 30 316.250 ± 9.614 ns/op
ToArrayBench.zero 100 hashset avgt 30 284.431 ± 6.201 ns/op
# --------------------------------------------------------------------------
因此至少五年以来,zero 比 sized 要更快。
还要注意性能是如何随着 JDK 的改进提高点。人们常常会听到“Java 很慢”的声音,这些声音来自被过时的 JVM 束缚的人们。 更新它!(尽管存在一些真正没解决的性能问题。只有新的、被过度炒作的平台才没有问题,因为还没有人关心这些问题)
结论
综上所述,我们可以将初步答案推广到实际的结论:
- 反射创建数组的性能根本不影响
toArray(new T[0])的情况,因为Arrays.newArray现在被 VM 处理得很好。 因此 PMD 和 IDEA 的静态分析规则的前提在今天是无效的。This is the first-order effect at play here, 其余的是不同toArray实现细节之间的差异。 Object[] toArray()情况下的向量化 arraycopy 比toArray(new T[size])和toArray(new T[0])中需要类型检查的 arraycopy 快得多。 唉,当我们想得到T[]时,这对我们没有帮助。- 小数组上的
toArray(new T[size])与toArray(new T[0])之间的一个重要区别预测大小的能力, 这可能是因为size是从常量中被加载,来自静态已知的表达式,或涉及一些其他的神秘魔法。 当在集合自身以外查询size()时,我们需要成功地内联该方法,并期望该方法是O(1)的。 雪上加霜的是,如果集合大小在查询size()和调用toArray()之间发生了变化,我们就彻底搞砸了。 - 但是
toArray(new T[size])和toArray(new T[0])竞争的故事中更重要的部分是归零消除, 这基于 VM 判断新分配的数组是否已经完全被填充的能力。当前的实验表明,至少在ArrayList案例下, 内部分配的数组速度更快,但外部分配的数组有机会借助相同的机制优化。如果我们能够完全消除归零, 那么上条建议中关于size的一些警告可以放宽一些。
一句话总结:toArray(new T[0]) 看起来更快、更安全、更干净,因此现在应该是默认选择。
未来的 VM 优化可能会消除 toArray(new T[size]) 和它之间的性能差距,使现在“被认为是最优的”用法和实际上最优的一致。
未来 toArray API 的进一步改进将遵循与 toArray(new T[0]) 相同的逻辑——集合本上应该创建合适的存储。
Parting Thoughts
性能建议是很有趣的。他们的保质期是有限的,特别是在您不了解它们的背景,也懒得去追踪世界是如何演变的的时候。 它们的适用性经常受到之一,许多建议没有追踪来验证实验结果。这就是为什么如果您真的想要最佳性能,您需要安排一组专门的、精通如何审查性能并提出建议人员。
但是大多数时候,直白的代码已经足够快了,所以不需要再对针尖上的天使进行哲学思考,回去工作吧。 99.9% 的应用不需要专门的性能工程师团队;相反,他们需要让开发人员专注于编写清晰的可维护的代码, 并在代码无法满足性能需求的时候进行一些测量和调整,消除不必要的缺陷。
当长期的性能知识(例如 “使用预先分配好大小的数组调用 toArray()”)被嵌入到工具中时,这种理智的开发实践有时会受到污染。 当作为“快速提示”可用时会更加讨厌,甚至立即让人悲观。
